
[모니터링] 2 Elasticsearch 모니터링
들어가면서
앞서 1편에서 언급한 서버 자원 모니터링 대시보드와 Jenkins를 이용한 CI/CD 환경을 구축한 이후로는 서버에 직접 접속할 일이 거의 없어졌습니다. 단 하나, 문제가 생겼을 때 로그를 확인할 때만 서버에 접속해야 했습니다. 그러다 보니 자연스럽게 서버에 접속하지 않고도 로그를 실시간으로 확인할 수 있고, 로그를 보존할 수 있는 시스템이 필요하다고 느꼈습니다.
그래서 서버에 로그 모니터링 시스템을 구축했습니다. Filebeat로 로그를 수집하고 Logstash로 가공한 후 Elasticsearch에 적재한 후 그 데이터를 Kibana 대시보드를 통해 실시간으로 확인하는 방식입니다. 추가로 이 때 수집되는 nginx 로그를 사용해서 웹 모니터링 대시보드도 운영하고 있습니다.
로그 모니터링 시스템과 웹 모니터링 대시보드는 민감한 정보가 많이 포함되어 있기 때문에 블로그에서는 따로 다루지 않을 예정입니다. 오늘 다룰 것은 바로 이 Elasticsearch를 모니터링하는 Grafana 대시보드입니다.
Elasticsearch, Kibana 등으로 이뤄진 파이프라인은 예전에 개인 프로젝트하면서 다뤄본 적이 있었지만 실제 운영 환경에서 장기간 사용해본 것은 이번이 처음이었습니다. 그래서 처음에는 시행착오가 많았습니다. 예를 들어 로그를 보려고 할 때 갑자기 Kibana 대시보드에 접속할 수 없는 일이 발생했습니다. 원인은 다양했습니다. 남은 용량이 부족해지면 Elasticsearch가 읽기 전용 모드로 변한다거나, Unassigned shards가 너무 많아 클러스터가 이를 재할당하는 데 리소스를 쏟느라 새 요청에 제대로 대응하지 못하는 등의 이슈였습니다.
이슈에 대응하면서 Elasticsearch의 내부 동작 원리에 대해 더 자세히 알 수 있었고, 모니터링 대시보드를 구축할 필요성도 느꼈습니다. 대시보드 구축 후, Unassigned Shards가 1개 이상 발생하는 등 이상 징후가 생기면 바로 알람이 오는 알람 시스템도 구축했습니다. 알람 시스템 덕분에 문제 발생 전에 미리 조치를 취할 수 있었고 이후로는 필요할 때 Kibana 서버에 접속하지 못하는 일이 사라졌습니다.
오늘은 해당 Dashboard의 각 지표를 살펴보면서 제가 경험한 이슈를 토대로 어느 지표를 중점적으로 모니터링 해야 하는지 공유하고자 합니다.
대시보드 전체 구성
들어가기에 앞서 전체 설명은 아래와 같습니다. 더 자세한 내용은 아래 각 섹션에서 설명합니다.


Cluster Overview (클러스터 개요)
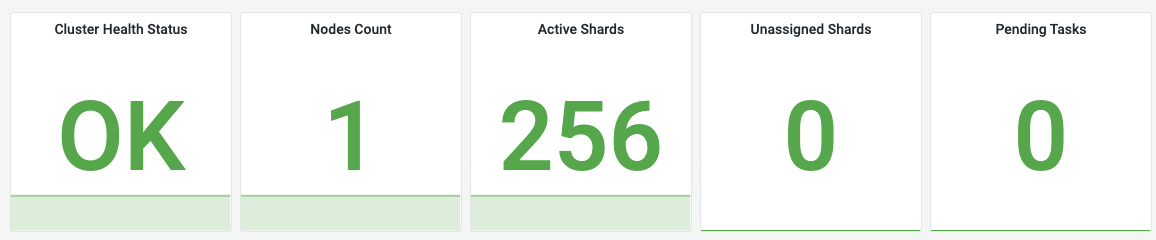
Cluster Health Status (클러스터 상태)
의미: 클러스터의 전반적인 건강 상태를 색상(Green, Yellow, Red)으로 나타냅니다.
| 상태 | 의미 |
|---|---|
| 🟢 Green | 모든 프라이머리 샤드와 레플리카 샤드가 정상적으로 할당된 상태입니다. |
| 🟡 Yellow | 프라이머리 샤드는 정상이나 일부 레플리카 샤드가 할당되지 않은 상태입니다. 데이터 접근은 가능하나 가용성 위험이 존재합니다. |
| 🔴 Red | 하나 이상의 프라이머리 샤드가 할당되지 않아 일부 데이터에 접근할 수 없는 심각한 상태입니다. |
관찰 포인트: 상태가 Yellow나 Red로 변할 경우, 즉시 Unassigned Shards 지표를 확인하고 원인 파악이 필요합니다.
Nodes Count (노드 수)
의미: 현재 클러스터에 참여하여 정상 동작 중인 서버(노드)의 총 개수입니다.
관찰 포인트:
- 설계된 클러스터의 전체 노드 수와 일치하는지 확인해야 합니다.
- 숫자가 줄어들었다면 특정 노드의 프로세스가 다운되었거나 네트워크 단절이 발생했음을 의미하므로 즉각적인 복구가 필요합니다.
Active Shards (활성 샤드 수)
의미: 클러스터 내에서 정상적으로 동작하며 데이터를 처리하고 있는 프라이머리 및 레플리카 샤드의 총합입니다.
관찰 포인트:
- 클러스터 규모와 데이터 양에 따라 정상 범위가 달라지지만, 급격한 수치 변화는 인덱스 삭제나 대량 로딩, 혹은 노드 이탈을 암시합니다.
- 노드 수 대비 샤드 수가 너무 많을 경우 성능 저하의 원인이 될 수 있습니다.
Unassigned Shards (미할당 샤드 수)
의미: 클러스터에 존재하지만 공간 부족이나 설정 문제 등으로 인해 어떤 노드에도 할당되지 못한 샤드의 수입니다.
관찰 포인트:
- 정상 상태에서는 반드시 0이어야 합니다.
- 수치가 0보다 크다면 클러스터 상태가 Yellow 혹은 Red로 변경됩니다. 주로 디스크 용량 부족, 노드 복구 중, 혹은 샤드 할당 규칙 위반 시 발생합니다.
Pending Tasks (대기 중인 작업)
의미: 마스터 노드에서 처리하기 위해 대기열에 쌓여 있는 클러스터 수준의 작업(인덱스 생성, 매핑 업데이트, 샤드 재할당 등)의 개수입니다.
관찰 포인트:
- 정상적인 경우 0에 가깝게 유지되어야 합니다.
- 이 수치가 지속적으로 높다면 마스터 노드가 부하를 견디지 못하고 있음을 의미하며, 클러스터의 설정 변경이나 상태 조회가 매우 느려질 수 있습니다.
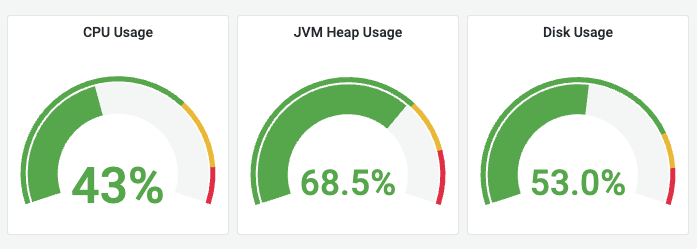
CPU Usage (CPU 사용률)
의미: 노드 서버의 CPU 자원 점유율을 나타냅니다.
관찰 포인트:
- 지속적 고부하: 80% 이상의 수치가 지속될 경우 검색 및 인덱싱 성능이 급격히 저하됩니다.
- 복잡한 집계 쿼리(Aggregation)나 대량의 쓰기 작업이 집중될 때 급증하는 경향이 있습니다.
JVM Heap Usage (JVM 힙 메모리 사용률)
의미: Elasticsearch 프로세스가 데이터 처리를 위해 사용하는 Java 가상 머신(JVM)의 메모리 점유율입니다.
관찰 포인트:
| 임계값 | 상태 |
|---|---|
| 75% 초과 | 가비지 컬렉션(GC)이 빈번해지며 성능이 저하됩니다. |
| 85~90% 도달 | ‘서킷 브레이커’가 작동하여 새로운 쿼리 요청을 거부할 수 있으며, 이는 곧 OOM(Out Of Memory) 장애로 이어질 수 있습니다. |
Disk Usage (디스크 사용률)
의미: 데이터를 저장하는 물리적 디스크의 저장 공간 사용량입니다.
관찰 포인트 — Elasticsearch 워터마크(Watermark) 기준:
| 임계값 | 동작 |
|---|---|
| 85% (Low) | 새로운 샤드 할당이 중지됩니다. |
| 90% (High) | 해당 노드의 샤드를 다른 노드로 강제 이동시키려 시도합니다. |
| 95% (Flood stage) | 인덱스가 Read-only 상태로 강제 전환되어 데이터 저장이 불가능해집니다. |
Search & Indexing Performance (검색 및 인덱싱 성능)
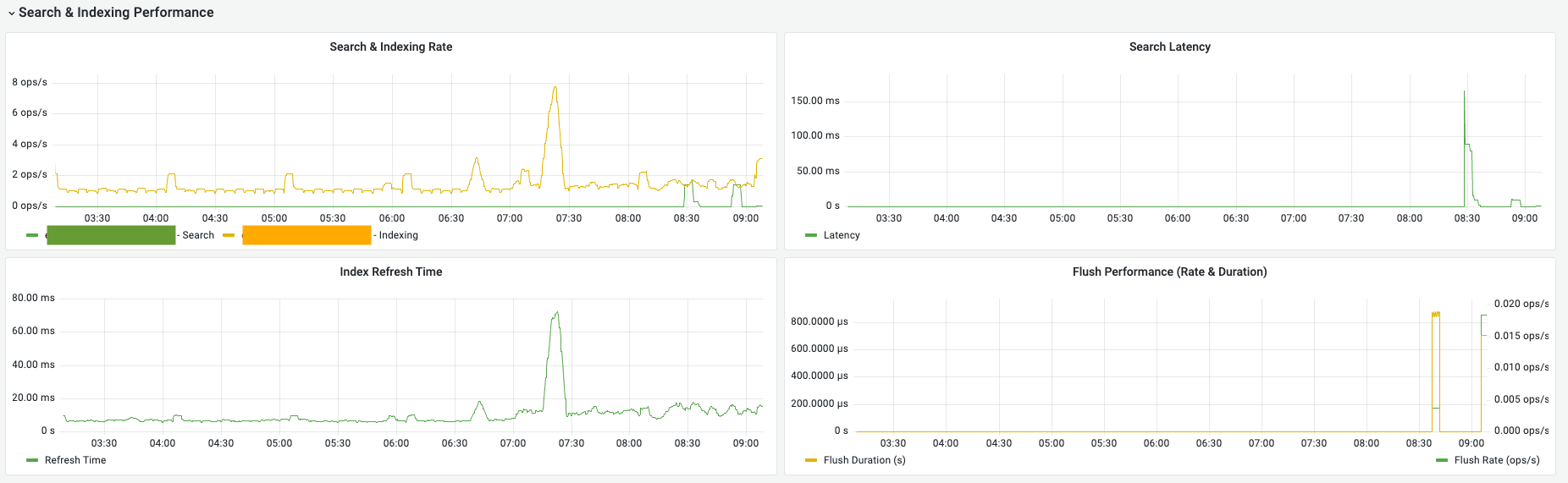
Search & Indexing Rate (검색 및 인덱싱 처리량)
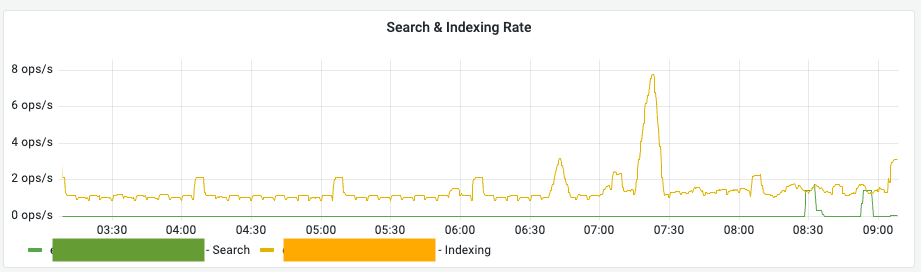
의미: 한 차트에 두 가지 트래픽 지표가 표시됩니다.
- Search (초록색 선): 초당 처리되는 조회(Query) 요청 수입니다.
- Indexing (노란색 선): 초당 처리되는 데이터 입력/업데이트 작업 수입니다.
관찰 포인트: 특정 시점에 노란색 선(Indexing)이 급증하면 시스템 전반의 CPU와 메모리 사용량이 함께 상승하므로 주의 깊게 살펴야 합니다.
Search Latency (검색 지연 시간)
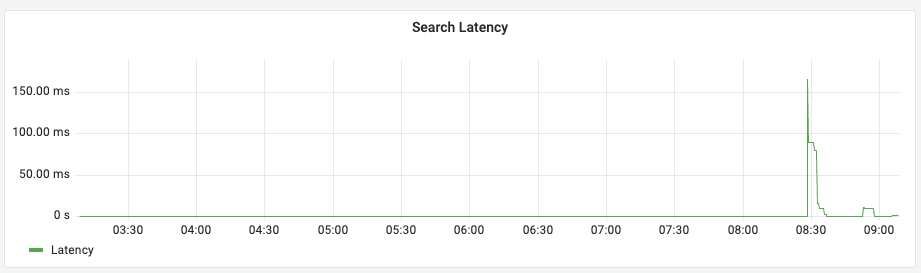
의미: 사용자가 검색을 요청했을 때 응답까지 걸리는 평균 시간(ms)입니다. (초록색 선)
관찰 포인트: 평소보다 선이 위로 튀는 구간(Spike)은 무거운 쿼리가 실행되었거나 시스템 자원이 부족함을 뜻합니다. 서비스 품질(SLA) 관리의 핵심 지표입니다.
Index Refresh Time (리프레시 소요 시간)
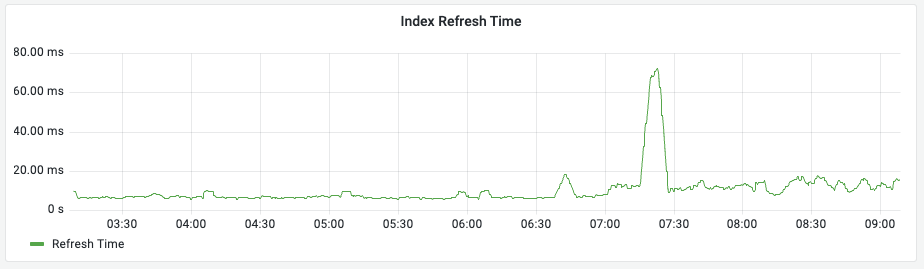
의미: 입력된 데이터를 검색 가능하도록 메모리에 반영하는 데 걸리는 시간입니다. (초록색 선)
관찰 포인트: 이 시간이 길어지면 데이터 입력과 검색 반영 사이의 시차가 발생합니다. 주로 디스크 I/O 성능이 한계에 도달했을 때 수치가 상승합니다.
Flush Performance (Flush 성능)
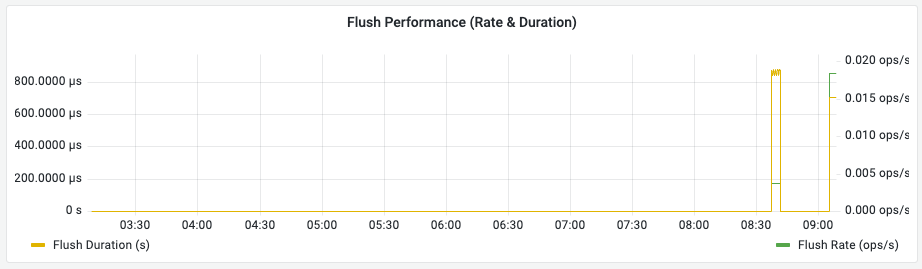
의미: 메모리의 데이터를 디스크로 영구 저장(Commit)하는 성능을 두 가지 관점에서 보여줍니다.
- Flush Duration (노란색 선): 한 번의 Flush 작업에 소요된 시간입니다. (단위: s)
- Flush Rate (초록색 선): 초당 발생하는 Flush 작업의 빈도입니다. (단위: ops/s)
관찰 포인트:
- Duration(노란색)이 길어진다는 것은 디스크 쓰기 속도가 느려졌다는 의미입니다.
- Rate(초록색)가 비정상적으로 높다면 잦은 커밋으로 인해 시스템 부하가 가중되고 있음을 뜻합니다.
JVM & Garbage Collection
JVM은 효율적인 메모리 관리를 위해 데이터를 생성 시기에 따라 두 영역으로 나누어 관리하며, 각 영역을 청소하는 것을 GC(Garbage Collection)라고 합니다.
| 영역 | 설명 |
|---|---|
| Young 영역 | 갓 생성된 객체들이 머무는 곳입니다. 여기서 발생하는 Young GC는 속도가 매우 빠르고 잦은 것이 정상이며, 시스템 성능에 큰 영향을 주지 않습니다. |
| Old 영역 | Young 영역에서 오래 살아남은 객체들이 이동하는 곳입니다. 여기서 발생하는 Old GC는 속도가 매우 느리며, 실행되는 동안 시스템이 일시적으로 멈추는 현상(Stop-the-world)을 유발하므로 최대한 발생하지 않아야 합니다. |
GC Count (GC 발생 횟수)
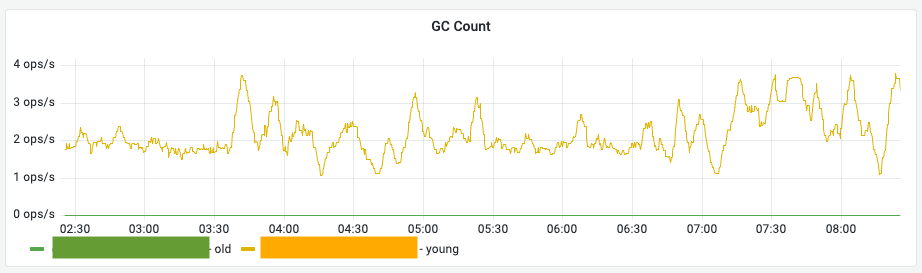
의미: 각 메모리 영역을 청소한 횟수입니다.
- Young (노란색 선): 신규 데이터 영역 청소 — 잦은 발생은 정상입니다.
- Old (초록색 선): 장기 데이터 영역 청소 — 최대한 발생하지 않아야 합니다.
관찰 포인트 — Old GC 주의: 초록색 선이 빈번하게 감지된다면 메모리 누수나 가용 메모리 부족을 의미하며, 성능 저하의 결정적 원인이 됩니다.
GC Duration (GC 소요 시간)
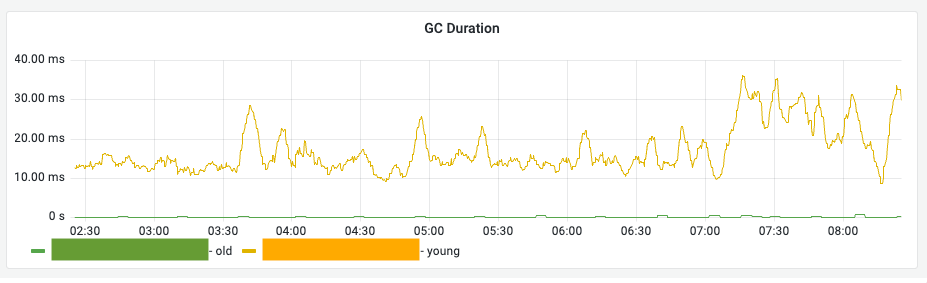
의미: 청소 작업으로 인해 시스템이 부하를 받거나 일시 정지되는 시간입니다.
- Young (노란색 선): Young GC 소요 시간
- Old (초록색 선): Old GC 소요 시간
관찰 포인트 — Stop-the-world 감지: Old GC Duration(초록색)이 상승하면 시스템이 완전히 멈추는 현상이 길어지고 있다는 뜻입니다. 이는 Search Latency를 직접적으로 상승시키는 주범입니다.
Index Statistics (인덱스 통계)
Index Size TOP 5 (주요 인덱스 용량)
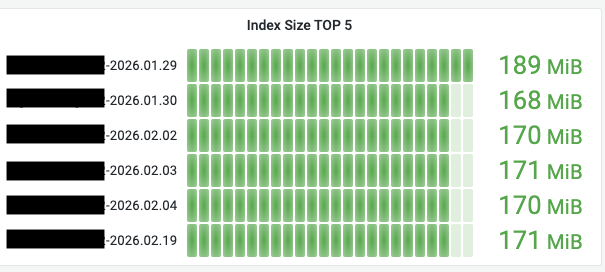
의미: 클러스터 내에서 가장 많은 디스크 용량을 차지하고 있는 상위 5개 인덱스의 개별 크기입니다.
관찰 포인트 — 용량 불균형: 특정 인덱스의 크기가 비정상적으로 커지고 있다면, 해당 인덱스의 샤드 개수가 적절한지 혹은 오래된 데이터를 정리(ILM 정책 등)해야 하는지 검토해야 합니다.
Docs Count (Sum) (전체 문서 수)
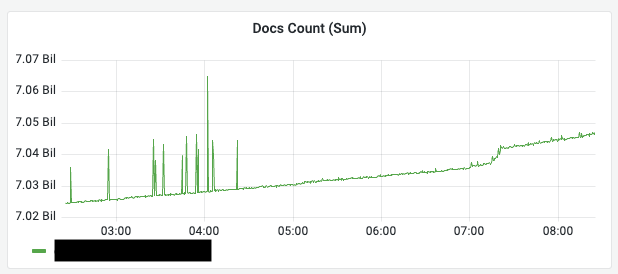
의미: 클러스터에 저장된 모든 유효 문서의 총합입니다.
관찰 포인트 — 데이터 수집 확인: 수집 트래픽에 따라 선형적으로 증가하는 것이 정상입니다.
- 수치가 급감한다면 데이터 유실을 의심해야 합니다.
- 수치가 급증한다면 중복 수집이나 루프 발생을 의심해야 합니다.
Deleted Docs (Sum) (삭제된 문서 수)
의미: 삭제 명령이 내려졌지만 아직 디스크에서 물리적으로 제거되지 않고 ‘삭제 마킹’만 된 문서의 수입니다.
관찰 포인트:
- 성능 영향: 삭제된 문서가 너무 많으면 검색 시 해당 문서를 걸러내는 오버헤드가 발생하여 성능이 저하됩니다.
- 정리 시점: Elasticsearch는 백그라운드에서 세그먼트 병합(Merge)을 통해 이 문서들을 정리합니다. 수치가 지속적으로 높다면 디스크 I/O 부하로 인해 병합 작업이 밀리고 있는 것일 수 있습니다.