
[모니터링] 1 서버 모니터링
들어가면서
저는 현재 회사에서 ‘나홀로 데이터 엔지니어’로서 데이터 수집 파이프라인 설계부터 최종 모델 배포, 그리고 그 모든 서비스가 돌아가는 인프라 운영까지 전 과정을 담당하고 있습니다. 데이터 엔지니어링은 자신이 있었지만 실제 유저가 있는 24시간 무중단 플랫폼 운영은 처음이었기에 우여곡절이 많았습니다.
초기에 가장 당황스러웠던 일은 서버가 갑자기 다운되는 일이었습니다. ‘영인님, 서버가 멈췄어요!’ 라는 메세지를 받으면 자다가도 일어나서 복구하고, 아침에 눈 뜨면 가장 먼저 서버가 괜찮은지 확인하곤 했습니다. 저 개인의 불편함도 불편함이었지만 무엇보다 우려되는 것은 유저의 불편함이었기 떄문입니다.
그래서 저는 이 문제를 제가 가장 잘 하는 방식으로 접근하기로 했습니다. 바로 데이터입니다. 문제를 해결하기 위해서는 원인이 무엇인지 알아야겠다고 생각했습니다. 다운되는 원인이 CPU인지, 메모리인지, 서버가 다운 되는 시점에 사용량 패턴은 어땠는지, 데이터를 수집하고 시각화해서 확인해보기로 했습니다. 그래서 저는 서버 자원 사용량을 수집해 모니터링 대시보드를 구축했습니다.
오늘 하고자 하는 이야기는 바로 이 대시보드입니다.
대시보드를 구축하고 나니 사용량 패턴이 보였습니다. 패턴에 따라 해결 방식을 유연하게 적용했습니다. 예를 들어 특정 시점에 피크가 튄다면 해당 시점에 수행된 프로세스를 찾아 원인을 분석했습니다. 만약 꾸준히 사용량이 높다면 운영 리소스에 문제가 있다는 뜻이므로 바로 해야할 일을 파악하고 착수할 수 있었습니다.
이렇게 경험이 쌓이다보니 장애가 발생하는 임계값이 보이기 시작했습니다. CPU 사용량이 특정 수치를 넘기면 미리 조치를 취하는게 좋다거나, 이 시점에는 유저의 접속량이 많으니 어느 정도 수치까지는 괜찮다는 저 나름대로의 기준이 생겼습니다. 그래서 이 기준에 맞춰서 특정 임계값이 넘으면 제게 알람을 보내는 알람 시스템을 구축했습니다.
알람 시스템을 구축하자 서버에 문제가 발생하기 전에 미리 알고 조치할 수 있었습니다. 대시보드를 계속 들여다볼 필요도 없어졌습니다. 알람이 왔을 때만 대시보드에 접속해서 문제를 파악하고 조치하는 식으로 업무 방식이 바뀌었고, 이렇게 확보한 시간은 신규 서비스 구현과 기존 서비스 유지 보수라는 더 중요한 일에 투자할 수 있게 되었습니다.
무엇보다 대시보드와 알람 시스템을 구축한 이후에는 4년간 단 한번의 서버 다운없이 안정적으로 서버를 운영할 수 있었습니다.
서버를 운영할 때 항상 많은 도움이 되었던 대시보드이기 때문에 서버를 운영하고 계시는 다른 분들께도 도움이 되면 좋겠다는 생각으로 이 글을 작성하게 되었습니다. 제가 모니터링하고 있는 지표와 그 지표에서 중요하게 보고 있는 부분을 정리해서 공유합니다. 이 글을 읽고 계시는 분들도 제 대시보드를 참고하셔서 처하신 상황에 맞는 대시보드를 구현하실 수 있기를 응원합니다.
대시보드 전체 구성
들어가기에 앞서 전체 설명은 아래와 같습니다. 더 자세한 내용은 아래 각 섹션에서 설명합니다.

Quick Overview
이 영역은 서버 상태를 한 눈에 확인하기 위한 요약 섹션입니다. 대부분의 경우에는 이 섹션만 확인합니다. 여기서 이상 징후가 보이면 아래 상세 지표에서 추가로 확인하는 식입니다.
① Uptime (가동 시간)
의미: 서버가 마지막 재부팅 이후 얼마나 오랫동안 중단 없이 작동했는지를 나타냅니다.
관찰 포인트:
- 가동 시간이 너무 길면 보안 패치나 커널 업데이트가 누락되었을 수 있으므로 정기적인 점검 계획을 확인해야 합니다.
- 장기 가동 시 미처 해제되지 못한 좀비 프로세스나 메모리 누수(Memory Leak) 등으로 인해 자원이 누적되어 성능이 저하될 수 있습니다. 시스템 안정성을 위해 서비스 영향이 적은 시간대에 주기적인 재부팅을 권장합니다.
해석 (예시): 스크린샷의 26.3 week는 약 6개월간 서버가 한 번도 꺼지지 않고 안정적으로 운영되었음을 의미합니다.
② CPUs & Load Average (코어 수와 부하 평균)
의미: 서버의 물리적/논리적 처리 용량(CPUs)과 현재 처리 중인 업무의 양(LA)을 나타냅니다.
관찰 포인트:
- LA > 코어 수: 서버의 처리 용량을 넘어 프로세스가 대기하고 있다는 위험 신호입니다.
- LA 수치는 반드시 해당 서버의 총 코어 수(CPUs)와 비교하여 상대적으로 해석해야 합니다.
해석 (예시): 코어 수가 8일 때 LA가 3.45라면, 전체 용량의 약 43%를 사용하여 안정적으로 업무를 처리 중인 상태입니다.
③ CPU Usage (CPU 사용률)
의미: 전체 연산 자원 중 현재 실제로 사용 중인 연산량의 비율입니다.
관찰 포인트:
- 일반적으로 80%를 지속적으로 상회할 경우 애플리케이션 최적화나 서버 사양 확장(Scale-up)을 검토합니다.
해석 (예시): 44%는 안정적인 수준입니다.
④ Available Memory (가용 메모리)
의미: 전체 RAM 중 현재 즉시 사용 가능한 여유 공간의 비율입니다.
관찰 포인트:
- 메모리가 100%에 근접하면 시스템이 프로세스를 강제 종료하는 OOM(Out Of Memory) 현상이 발생합니다. 최소 10~20%의 여유는 항상 유지되는지 확인하세요.
해석 (예시): 46.3%는 충분한 여유 공간을 확보하고 있는 상태입니다.
⑤ IOWait (I/O 대기율)
의미: CPU가 디스크나 네트워크 등 입출력 작업이 완료되기를 기다리며 대기하는 시간의 비율입니다.
관찰 포인트:
- 5% 이상 지속: 디스크 성능 저하, 과도한 DB 쿼리, 혹은 대량의 로그 기록 여부를 점검해야 합니다. 보통 디스크 사용률(Disk Usage) 지표와 함께 확인합니다.
해석 (예시): 0.0854%는 I/O 병목이 거의 없는 매우 쾌적한 상태입니다.
⑥ Disk Usage (디스크 사용률)
의미: 서버 저장 공간의 총 사용량입니다.
관찰 포인트:
- 로그 파일이나 임시 파일이 쌓여 90%를 넘기면 새로운 데이터를 기록할 수 없어 서비스 장애가 발생하므로 주기적인 청소가 필요합니다.
해석 (예시): 50.9%는 안전한 범위입니다.
⑦ Network Bandwidth Saturation (네트워크 포화도)
의미: 서버 네트워크 인터페이스의 최대 대역폭 대비 현재 사용량입니다.
관찰 포인트:
- 갑작스러운 수치 상승은 트래픽 폭주나 외부 공격(DDoS) 가능성을 시사하므로 주의 깊게 살펴봐야 합니다.
해석 (예시): 0.00%는 네트워크 부하가 거의 없음을 나타냅니다.
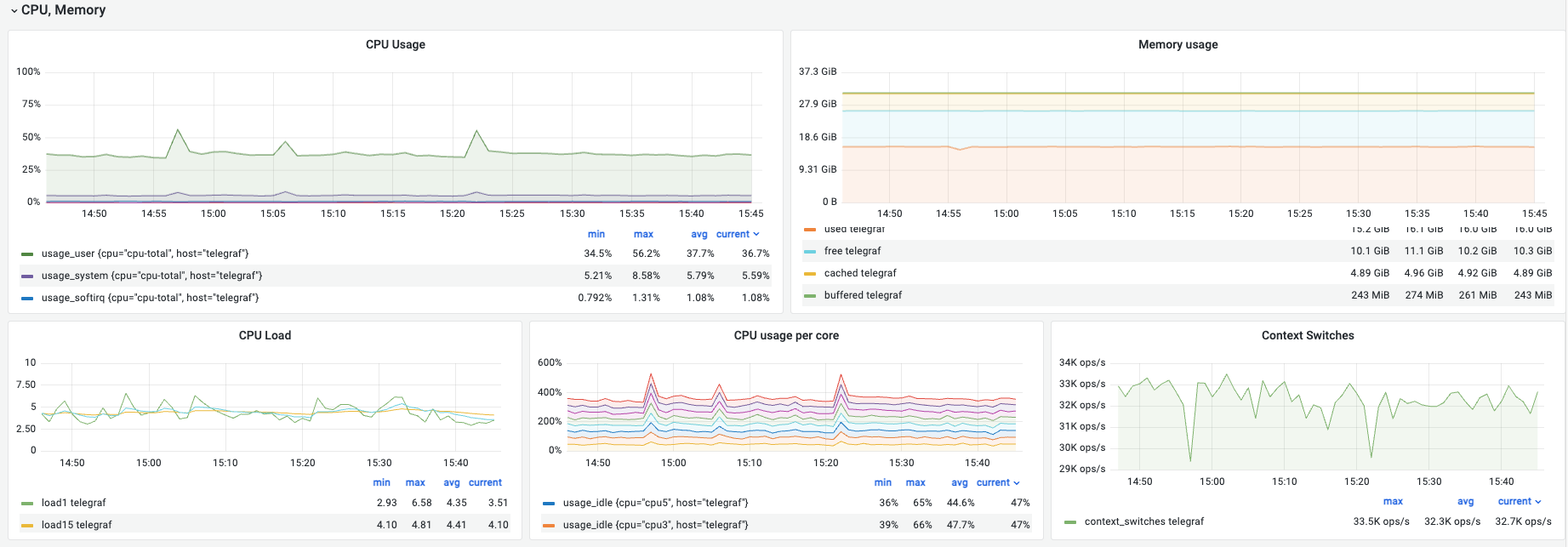
CPU, Memory
① CPU Usage 상세 (User / System / Softirq)
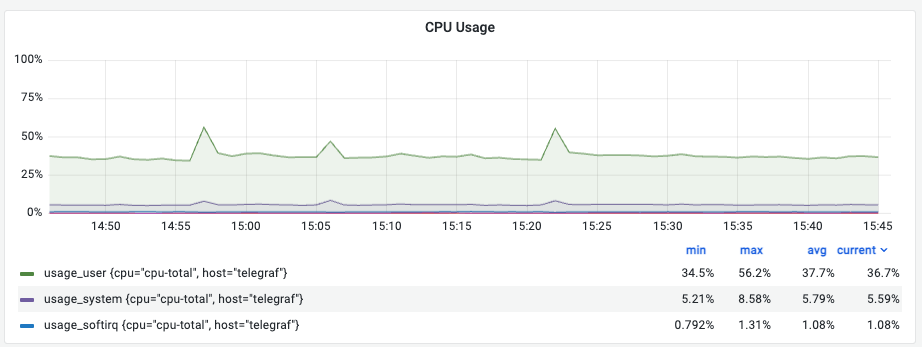
의미: CPU 사용량의 구체적인 구성을 보여줍니다.
- User: 애플리케이션 서비스 로직이 연산에 사용하는 비율입니다.
- System: 운영체제 커널이 사용하는 비율입니다.
- Softirq: 네트워크 패킷 처리 등 소프트웨어 인터럽트에 사용되는 비율입니다.
관찰 포인트:
- User 수치가 높다면 로직 최적화가 필요합니다.
- System이나 Softirq가 비정상적으로 높다면 네트워크 트래픽 폭주나 하드웨어 드라이버 문제를 의심해야 합니다.
해석 (예시): User(36.7%), System(5.59%), Softirq(1.08%)로 대부분의 자원이 실제 서비스 로직 처리에 집중되어 있는 이상적인 분포입니다.
② Memory Usage 상세 (Used / Free / Cached / Buffered)
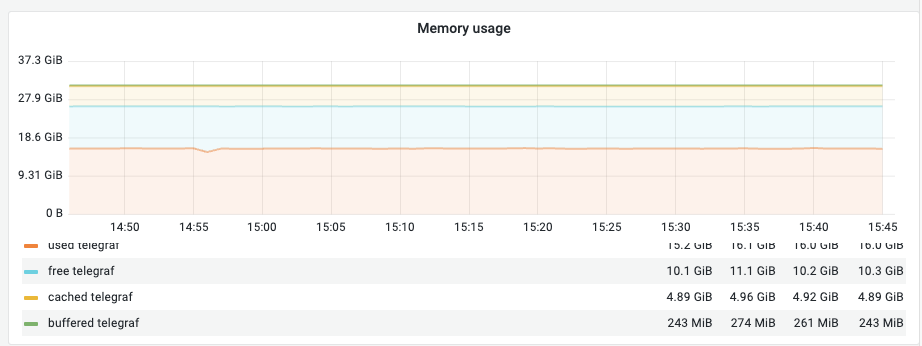
의미: 리눅스의 효율적인 메모리 관리 방식을 보여줍니다.
- Used: 실제 프로세스가 점유 중인 메모리입니다.
- Free: 완전히 비어있는 메모리입니다.
- Cached/Buffered: 성능 향상을 위해 커널이 임시로 데이터를 담아둔 공간입니다. (필요 시 즉시 비워져서 가용 메모리로 전환됩니다.)
관찰 포인트:
- 단순 Free 용량만 보기보다
Free + Cached + Buffered를 합친 실질 가용량을 확인하는 것이 중요합니다.
해석 (예시): Used(16.0 GiB) 외에 Cached(4.89 GiB) 등이 확보되어 있어 실제 물리적으로 비어있는 Free(10.3 GiB)보다 더 넓은 범위를 가용 영역으로 쓸 수 있습니다.
③ CPU Load (Load 1m vs Load 15m)
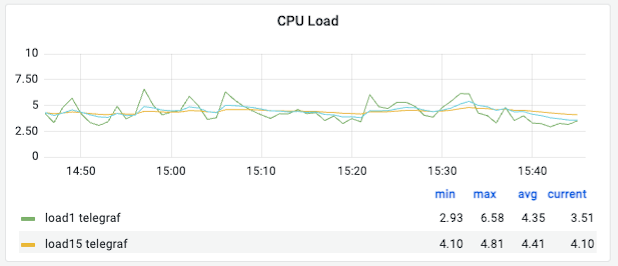
의미: 부하의 추세를 파악할 수 있습니다.
- Load 1: 최근 1분간의 부하 평균입니다.
- Load 15: 최근 15분간의 부하 평균입니다.
관찰 포인트:
- Load 1 > Load 15: 부하가 급격히 상승 중인 ‘진행 중인 장애’ 상황일 확률이 높습니다.
- Load 1 < Load 15: 피크 타임이 지나 부하가 줄어들고 있는 안정화 단계입니다.
해석 (예시): Load 1(3.51)이 Load 15(4.10)보다 낮습니다. 이는 조금 전 발생했던 일시적인 부하 피크가 지나가고 시스템이 다시 안정화되고 있음을 의미합니다.
④ CPU Usage per Core (코어별 사용률)
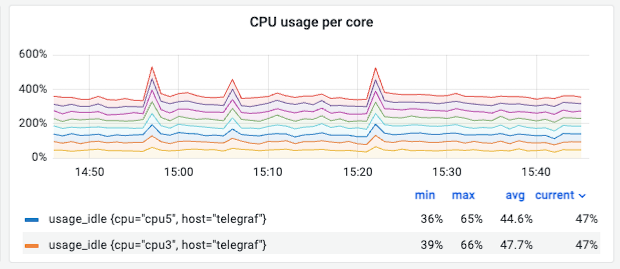
의미: 각 CPU 코어의 개별 사용률입니다.
관찰 포인트:
- 특정 코어에만 부하가 집중된다면 멀티스레딩이 제대로 활용되지 않고 있다는 신호입니다. 이 경우 워커 수 조정이나 병렬 처리 설정을 점검합니다.
해석 (예시): 8개 코어가 고르게 분산되어 사용 중이라면 이상적인 멀티코어 활용 상태입니다.
⑤ Context Switches (컨텍스트 스위치)
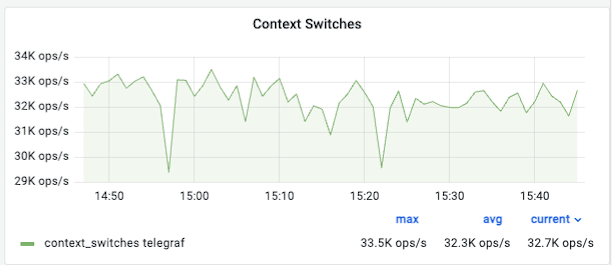
의미: CPU가 여러 프로세스를 번갈아 가며 처리하기 위해 작업 환경을 바꾸는 횟수입니다.
관찰 포인트:
- 수치가 평소보다 과도하게 높다면 (예: 수십만 단위 급증 시) 시스템이 실제 연산보다 프로세스 간 전환에 더 많은 자원을 낭비하고 있다는 뜻이며 성능 저하의 원인이 됩니다.
해석 (예시): 초당 약 32.7K번의 전환이 일어나고 있으며 그래프가 일정한 패턴을 유지하고 있어 정상적인 멀티태스킹 상태로 볼 수 있습니다.
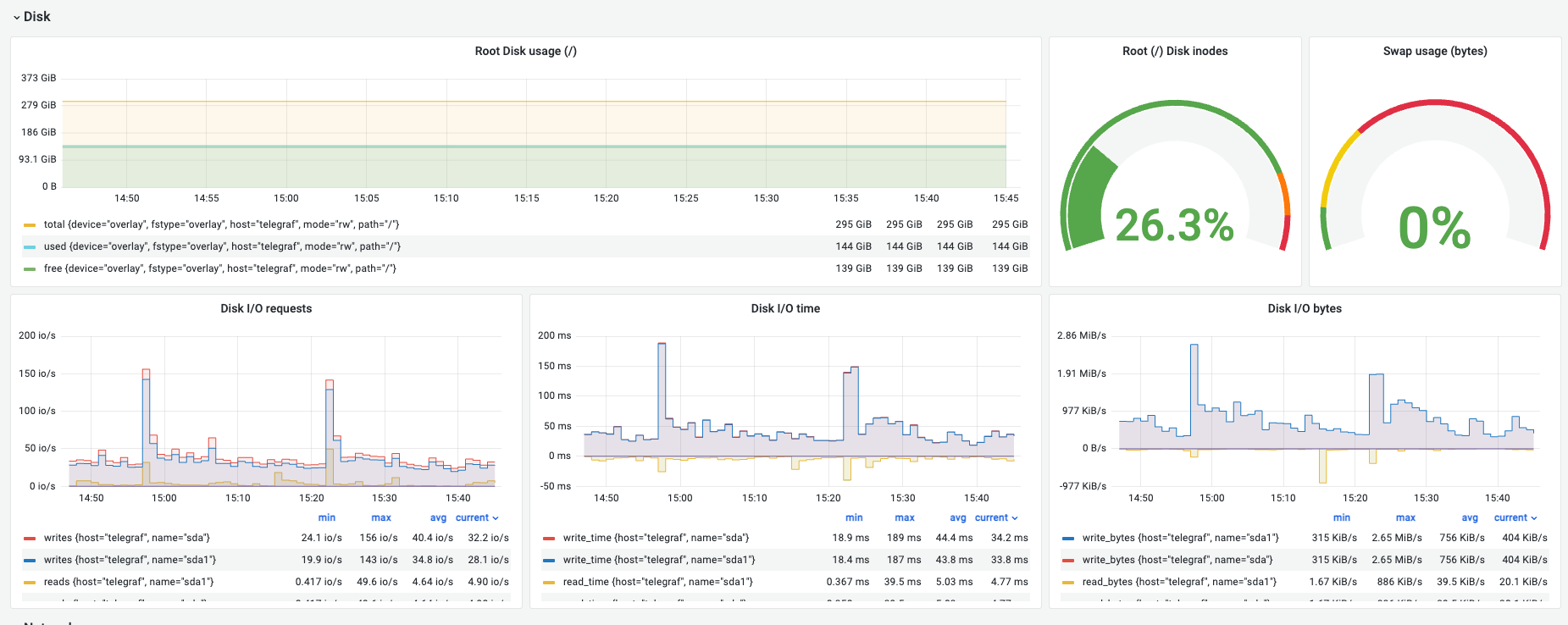
Disk
① Root Disk Usage (루트 디스크 사용량)
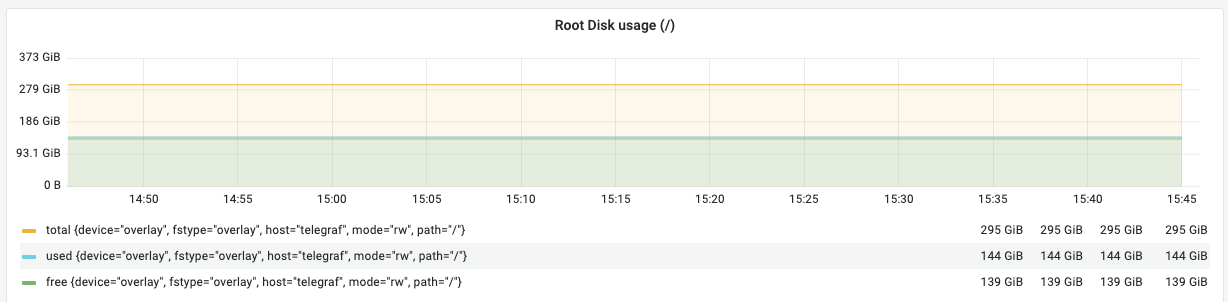
의미: 루트 디렉토리(/)의 물리적인 저장 용량 사용 현황입니다.
관찰 포인트:
- 80% 경계선: 용량이 80%를 초과하면 시스템 및 애플리케이션에서 에러 로그가 급증하며, 이 로그들이 남은 공간을 순식간에 채워 서버 전체가 중단(Hang)될 수 있습니다.
- 90% 이상이 되면 시스템 로그조차 기록되지 않아 장애 원인 파악이 불가능해집니다.
- 주기적으로
/var/log나/tmp폴더의 용량을 점검하여 불필요한 파일을 정리해야 합니다.
해석 (예시): 전체 295 GiB 중 144 GiB 사용 중으로 약 139 GiB의 여유가 있어 안전합니다.
② Root (/) Disk inodes (파일 개수 제한)
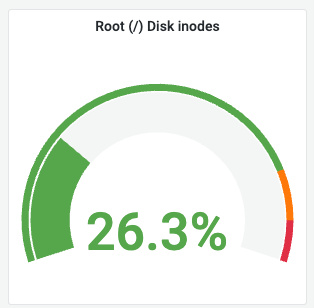
의미: 파일 시스템에서 생성 가능한 ‘파일 및 디렉토리 개수’의 제한입니다.
관찰 포인트:
- 중요: 디스크 용량이 많이 남아있더라도 Inodes가 100%가 되면 파일을 더 이상 생성할 수 없습니다.
- 수많은 작은 파일(세션 파일, 임시 이미지 등)을 생성하는 서비스에서 주로 발생하는 장애 원인입니다.
해석 (예시): 26.3%로 안정적입니다.
③ Swap Usage (스왑 사용량)
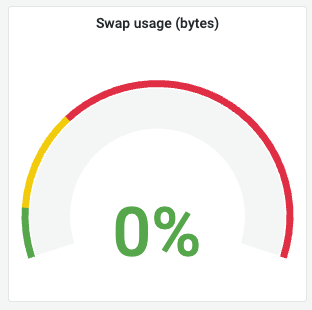
의미: 물리 메모리(RAM) 부족 시 디스크 일부를 빌려 메모리처럼 사용하는 비상 영역입니다.
관찰 포인트:
- Swap이 활발하게 사용되면 디스크 속도 한계로 인해 시스템 전체가 매우 느려지는 쓰레싱(Thrashing) 현상이 발생합니다.
- Swap 사용량이 증가한다면 물리 메모리 증설 혹은 메모리 누수 점검이 시급한 상황입니다.
해석 (예시): 0%로 물리 메모리 안에서 모든 연산이 원활하게 이루어지고 있습니다.
④ Disk I/O Requests (작업 횟수)
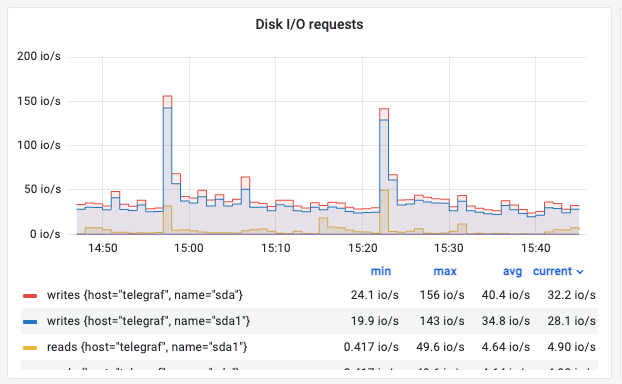
의미: 초당 발생하는 읽기/쓰기 명령의 횟수(IOPS)입니다.
관찰 포인트:
- 요청 횟수가 높다는 것은 잘게 쪼개진 데이터를 자주 읽고 쓰고 있다는 뜻입니다(Random I/O).
- DB 인덱스 스캔이나 로그 기록이 잦을 때 수치가 상승합니다.
해석 (예시): 쓰기 요청이 평균 30~40 io/s 발생하며 특정 시점에 156 io/s까지 튑니다. 일시적인 패턴이라면 정상이지만 지속적이라면 점검이 필요합니다.
⑤ Disk I/O Time (지연 시간/대기 시간)
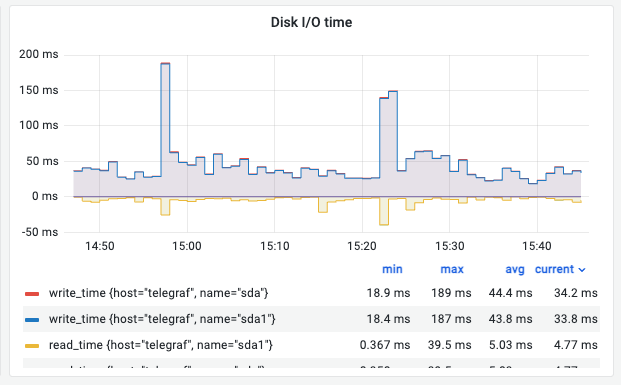
의미: 디스크 명령을 내린 후 실제로 완료되기까지 걸린 시간(Latency)입니다.
관찰 포인트:
- 성능 지표의 핵심: 이 수치가 높으면 디스크가 부하를 감당하지 못해 밀려 있는 상태입니다.
- 보통
10ms~100ms이내를 유지해야 하며, 지속적으로 수백 ms를 기록하면 사용자 응답 속도가 현저히 느려집니다.
해석 (예시): 쓰기 작업 시간이 피크 시 189ms까지 기록되었습니다. 부하 시점의 지연 시간을 확인하여 디스크 성능 한계를 파악할 수 있습니다.
⑥ Disk I/O Bytes (처리량)
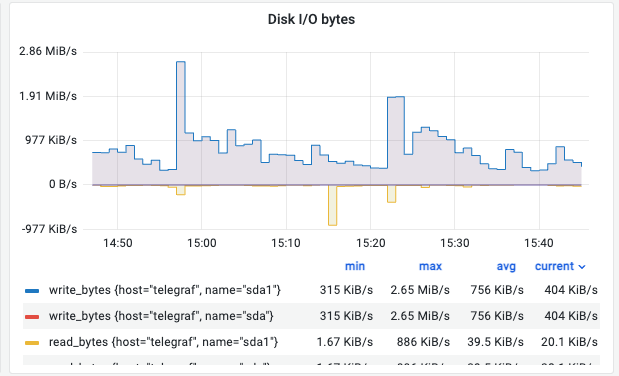
의미: 실제로 전송되는 데이터의 총 크기(Throughput)입니다.
관찰 포인트:
- 백업이나 대용량 파일 복사 시 이 수치가 급증합니다.
- 만약 I/O Requests(횟수)는 낮은데 Bytes(크기)만 높다면 큰 파일을 연속적으로 읽고 있는 것입니다(Sequential I/O).
해석 (예시): 초당 평균 400~700 KiB/s 정도의 데이터가 전송되고 있습니다.
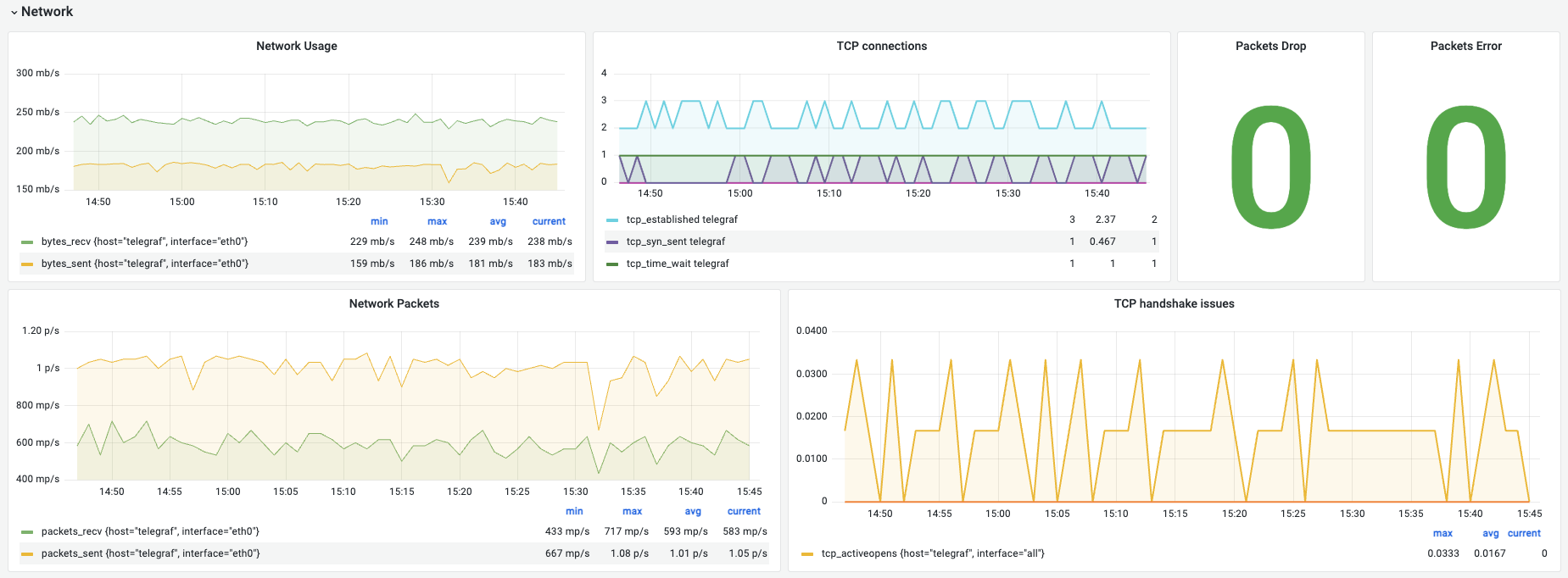
Network
① Network Usage (Bandwidth)
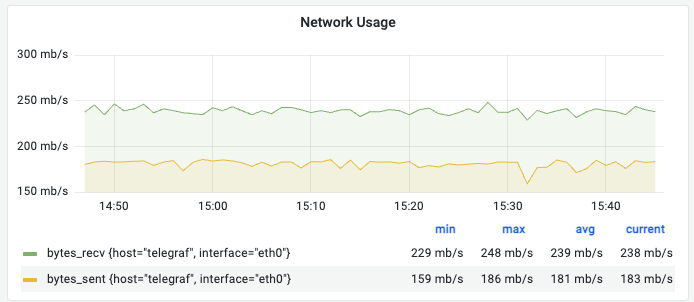
의미: 초당 주고받는 데이터의 총량(bytes_recv / bytes_sent)입니다.
관찰 포인트:
- 서비스의 트래픽 규모를 파악하는 기본 지표입니다.
recv가 많으면 업로드 트래픽이,sent가 많으면 다운로드/스트리밍 트래픽이 높은 것입니다.
해석 (예시): 받는 트래픽 약 238 mb/s, 보내는 트래픽 약 183 mb/s로 균형 있게 사용 중입니다.
② TCP Connections (TCP 연결 상태)
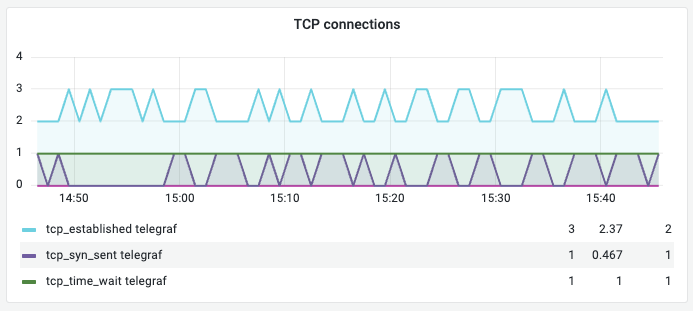
의미: 현재 연결된 세션의 상태별 개수입니다.
established: 연결됨syn_sent: 연결 시도 중time_wait: 종료 대기
관찰 포인트:
syn_sent가 비정상적으로 높으면 외부 서버와의 통신 지연을 의심합니다.time_wait가 너무 많으면 소켓 고갈 가능성을 점검해야 합니다.
해석 (예시): established 2개 등으로 매우 한산하고 안정적인 연결 상태입니다.
③ Packets Drop & Error (손실 및 오류)

의미: 네트워크 장비나 OS 수준에서 버려지거나 오류가 발생한 패킷의 수입니다.
관찰 포인트:
- 중요: 이 수치는 항상 0이어야 합니다. 0보다 커진다면 선로 불량, 스위치 오류, 혹은 커널 버퍼 부족 등을 의미하는 명확한 장애 신호입니다.
해석 (예시): 현재 0으로 매우 깨끗한 네트워크 상태를 유지하고 있습니다.
④ Network Packets (PPS)
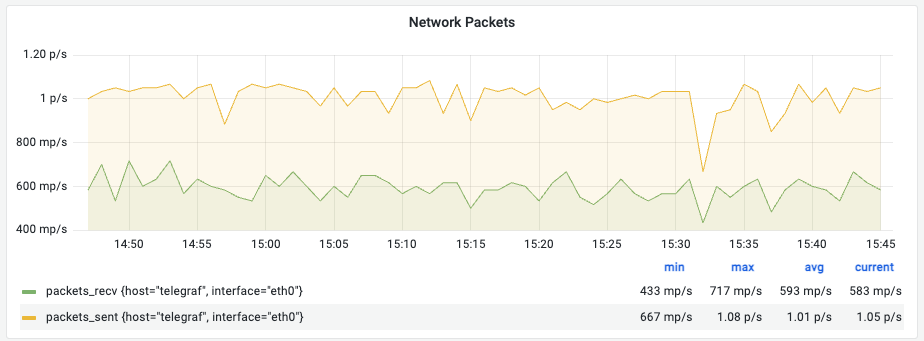
의미: 초당 전송되는 패킷의 개수(PPS)입니다.
관찰 포인트:
- 데이터 크기(Usage)는 작아도 패킷 개수가 많다면 작은 크기의 통신이 빈번한 ‘Small Packet’ 부하 상태임을 의미합니다.
해석 (예시): 초당 약 583~1050개의 패킷을 안정적으로 처리하고 있습니다.
⑤ TCP Handshake Issues (TCP 핸드셰이크 이슈)
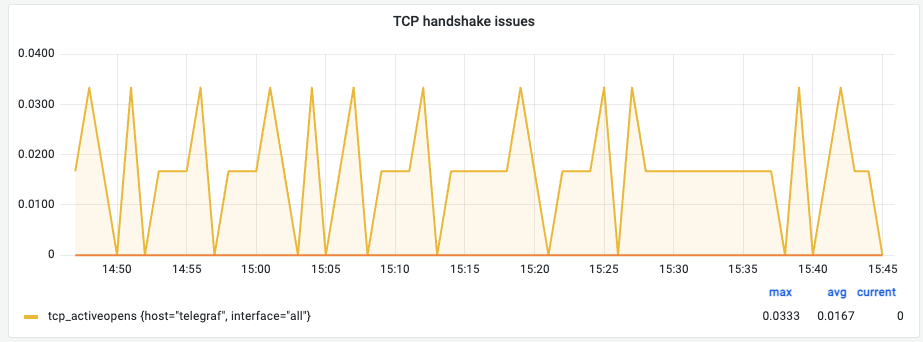
의미: TCP 연결 과정에서 발생하는 이슈(실패 등)를 보여줍니다.
관찰 포인트:
- 수치가 튀어오른다면 네트워크 불안정으로 인해 접속 요청이 간헐적으로 실패하고 있다는 뜻입니다. “접속이 가끔 안 돼요”라는 피드백이 올 때 가장 먼저 확인해야 합니다.
해석 (예시): 현재 0으로 안정적이며 이전의 작은 튐 현상도 즉시 해소되었습니다.