
[Azure Speaker Recognition] Python으로 Azure Speaker Recognition RESTful API 사용하기
Azure에서 제공하는 Speaker Recognition의 RESTful API를 Python으로 사용하는 튜토리얼입니다.
음성 서비스 구독
Speaker Recognition 서비스를 사용하기 위해서는 Azure의 음성 서비스(Speech Services)를 구독해야합니다.
만약 구독이 되어있는 분은 이 부분은 건너뛰셔도 됩니다.
-
Azure Portal에서 Cognitive Services를 검색한 뒤 선택합니다.
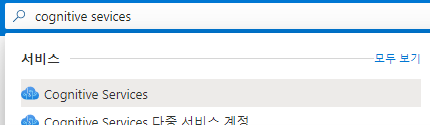
-
Cognitive Services 서비스 목록에서 음성 서비스(Speech Service)를 찾아 만들기 버튼을 클릭합니다.
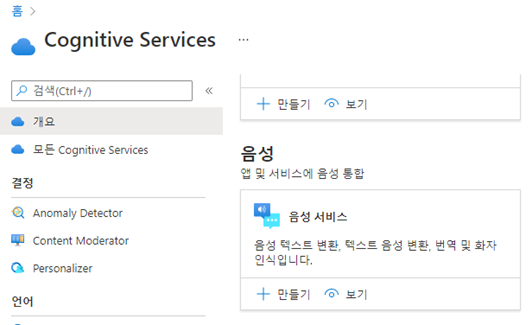
-
각 항목을 입력한 뒤 만들기 버튼을 클릭합니다. 다른 항목은 모두 자유롭게 설정 가능하지만 위치만큼은 반드시 미국 서부로 해야합니다. (Speaker Recognition은 현재 미국 서부에서만 지원) 그리고 가격 책정 계층의 경우 무료 F0이 가능하면 무료로 선택 해주세요.
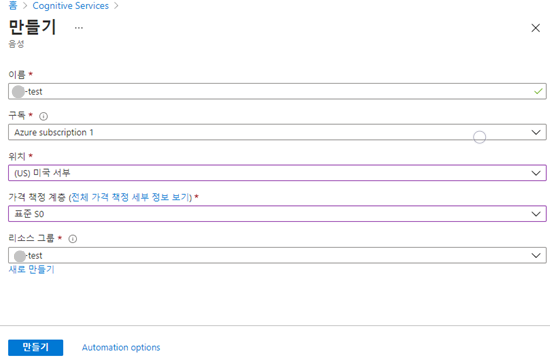
텍스트 종속 검증
기본 준비
(1) 필요 모듈을 Import합니다.
1
2
import requests
import json
(2) 필요 상수를 선언합니다.
1
2
3
4
endpoint = 'https://westus.api.cognitive.microsoft.com'
main_url = endpoint + '/speaker/verification/v2.0/text-dependent/profiles/'
sub_key = {Subscription-key}
profile_url = ''
- 참고: 구독키는 Azure Portal의 음성 서비스 항목을 선택한 뒤 목록의 키 및 엔드포인트를 클릭하면 확인할 수 있습니다.
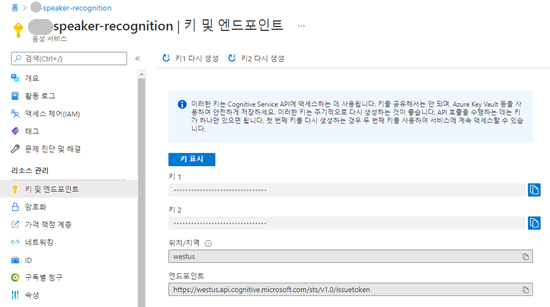
(3) 프로필 등록용 음성 파일 3개, 검증용 음성 파일 1개를 준비합니다. 형식은 .wav이며 1초 이상 녹음되어야 있어야 하고 텍스트 종속 검증이므로 암호를 포함하고 있습니다. 이번 튜토리얼에선 기본 암호인 “my voice is my passport verify me”를 사용했습니다.
음성 프로필 생성
(4) 음성을 등록할 프로필을 생성합니다.
1
2
3
4
5
6
7
8
9
10
11
def create_profile(sub_key):
header = {'Content-Type': 'application/json', 'Ocp-Apim-Subscription-Key': sub_key}
locale = json.dumps({'locale': 'en-us'})
r = requests.post(main_url, headers=header, data=locale)
# 추후 사용할 url도 함께 생성합니다.
global profile_url
profile_id = r.json()['profileId']
profile_url = main_url + profile_id
return r.json()
create_profile(sub_key)
프로필을 생성하고 나면 기존에 사용한 URL 끝에 프로필ID를 추가하여 해당 프로필에 접속하기 때문에 프로필을 생성하는 것과 동시에 Json에서 프로필ID를 추출하여 새로운 URL을 선언해주었습니다.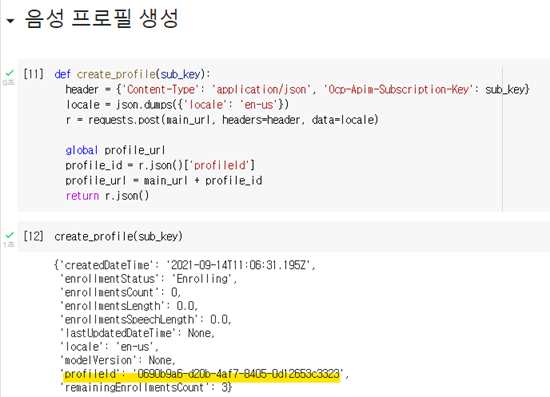
새롭게 생성된 URL은 아래처럼 확인할 수 있습니다.
음성 프로필 등록
(5) 음성 프로필에 기준이 될 음성을 등록합니다.
1
2
3
4
5
6
7
8
9
10
def enroll(sub_key, file_path):
enroll_url = profile_url + '/enrollments'
header = {'Content-Type': 'audio/wav; codecs=audio/pcm; samplerate=16000', 'Ocp-Apim-Subscription-Key': sub_key}
data = open(file_path, 'rb') # 요구하는 파일 형태가 binary이므로 rb 모드를 사용해야 요청 가능
r = requests.post(enroll_url, headers=header, data=data)
return r.json()
enroll(sub_key, r'Enroll1.wav')
enroll(sub_key, r'Enroll2.wav')
enroll(sub_key, r'Enroll3.wav')
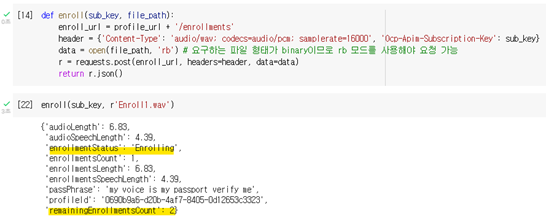
등록하고 나면 남은 파일 수나 파일 크기 등 관련 내용을 확인할 수 있으며 3개를 다 등록하고 나면 아래처럼 상태가 Enrolling에서 Enrolled로 바뀝니다.
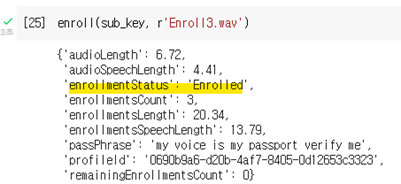
종속 음성 검증
(6) 음성이 모두 등록되었다면 검증 파일로 검증을 진행합니다.
1
2
3
4
5
6
7
8
def verify(sub_key, file_path):
verify_url = profile_url + '/verify'
header = {'Content-Type': 'audio/wav; codecs=audio/pcm; samplerate=16000', 'Ocp-Apim-Subscription-Key': sub_key}
data = open(file_path, 'rb')
r = requests.post(verify_url, headers=header, data=data)
return r.json()
verify(sub_key, r"Verification.wav")
Json으로 검증 결과를 확인할 수 있으며 유사도가 0에서 1사이로 표시됩니다. 1에 가까울수록 유사한 음성입니다.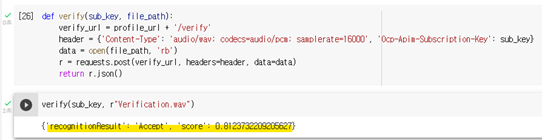
음성 프로필 삭제
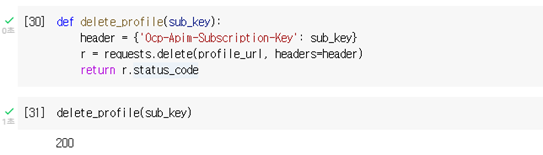
(7) 모든 작업이 끝났다면 음성 프로필을 삭제합니다. 삭제할 경우 Json값을 반환하지 않으므로 HTTP 연결 상태로 성공 여부를 확인합니다.
1
2
3
4
5
6
def delete_profile(sub_key):
header = {'Ocp-Apim-Subscription-Key': sub_key}
r = requests.delete(profile_url, headers=header)
return r.status_code
delete_profile(sub_key)
텍스트 독립 검증
기본 준비
(1) 필요 모듈을 Import합니다.
1
2
import requests
import json
(2) 필요 상수를 선언합니다.
1
2
3
4
endpoint = 'https://westus.api.cognitive.microsoft.com'
main_url = endpoint + '/speaker/verification/v2.0/text-independent/profiles/'
sub_key = {Subscription-key}
profile_url = ''
- 참고: 구독키는 Azure Portal의 음성 서비스 항목을 선택한 뒤 목록의 키 및 엔드포인트를 클릭하면 확인할 수 있습니다.
(3) 프로필 등록용 음성 파일 1개, 검증용 음성 파일 1개를 준비합니다. 형식은 .wav이며 텍스트 독립 검증이므로 특정 텍스트를 포함할 필요가 없습니다. 등록용 음성 파일은 20초 이상이어야 하며 검증용 음성파일은 4초 이상이어야 합니다. 
음성 프로필 생성
(4) 음성을 등록할 프로필을 생성합니다.
1
2
3
4
5
6
7
8
9
10
11
def create_profile(sub_key):
header = {'Content-Type': 'application/json', 'Ocp-Apim-Subscription-Key': sub_key}
locale = json.dumps({'locale': 'en-us'})
r = requests.post(main_url, headers=header, data=locale)
# 추후 사용할 url도 함께 생성합니다.
global profile_url
profile_id = r.json()['profileId']
profile_url = main_url + profile_id
return r.json()
create_profile(sub_key)
프로필을 생성하고 나면 기존에 사용한 URL 끝에 프로필ID를 추가하여 해당 프로필에 접속하기 때문에 프로필을 생성하는 것과 동시에 Json에서 프로필ID를 추출하여 새로운 URL을 선언해주었습니다.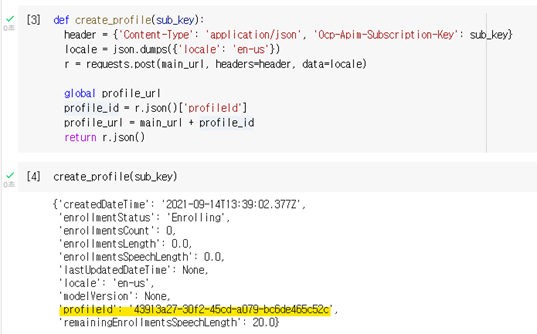
새롭게 생성된 URL은 아래처럼 확인할 수 있습니다.
음성 프로필 등록
(5) 음성 프로필에 기준이 될 음성을 등록합니다.
1
2
3
4
5
6
7
8
def enroll(sub_key, file_path):
enroll_url = profile_url + '/enrollments'
header = {'Content-Type': 'audio/wav; codecs=audio/pcm; samplerate=16000', 'Ocp-Apim-Subscription-Key': sub_key}
data = open(file_path, 'rb') # 요구하는 파일 형태가 binary이므로 rb 모드를 사용해야 요청 가능
r = requests.post(enroll_url, headers=header, data=data)
return r.json()
enroll(sub_key, r'Independent_Enroll.wav')
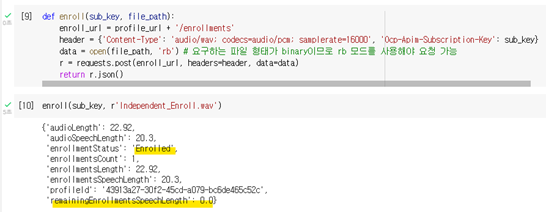
등록하고 나면 Json을 통해 관련 정보를 확인할 수 있으며 20초에서 시간이 모자라는 경우 남은 시간이 표시됩니다. 20초가 모두 등록되면 Enrolled로 바뀝니다.
[비교] 시간이 모자라는 경우
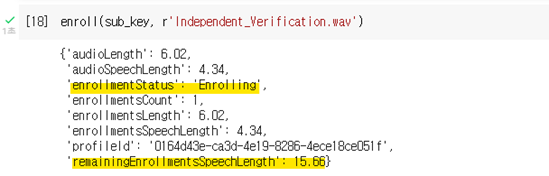
독립 음성 검증
(6) 음성이 등록되었다면 검증 파일로 검증을 진행합니다. 텍스트 종속 검증과 다르게 등록 음성 파일과 검증 음성 파일의 내용은 서로 연관되지 않아도 됩니다.
1
2
3
4
5
6
7
8
def verify(sub_key, file_path):
verify_url = profile_url + '/verify'
header = {'Content-Type': 'audio/wav; codecs=audio/pcm; samplerate=16000', 'Ocp-Apim-Subscription-Key': sub_key}
data = open(file_path, 'rb')
r = requests.post(verify_url, headers=header, data=data)
return r.json()
verify(sub_key, r"Verification.wav")
Json으로 검증 결과를 확인할 수 있으며 유사도가 0에서 1사이로 표시됩니다. 1에 가까울수록 유사한 음성입니다.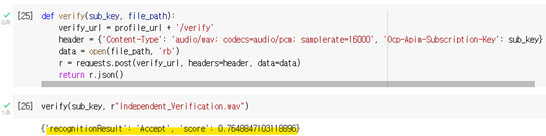
음성 프로필 삭제
(7) 모든 작업이 끝났다면 음성 프로필을 삭제합니다. 삭제할 경우 Json값을 반환하지 않으므로 HTTP 연결 상태로 성공 여부를 확인합니다.
1
2
3
4
5
6
def delete_profile(sub_key):
header = {'Ocp-Apim-Subscription-Key': sub_key}
r = requests.delete(profile_url, headers=header)
return r.status_code
delete_profile(sub_key)
화자 식별
기본 준비
(1) 필요 모듈을 Import합니다.
1
2
import requests
import json
(2) 필요 상수를 선언합니다.
1
2
3
4
5
endpoint = 'https://westus.api.cognitive.microsoft.com'
main_url = endpoint + '/speaker/identification/v2.0/text-independent/profiles/'
sub_key = {Subscription-key}
profile_url = ''
profile_ids = []
화자 식별의 프로세스는 텍스트 독립 검증과 거의 동일합니다. 주요 차이점은 단일 프로필로 비교 검증하는 것이 아니라 여러 음성 프로필과 비교하여 검증할 수 있다는 것입니다. 여러 개의 프로필을 사용하므로 프로필ID를 담을 리스트를 생성합니다.
- 참고: 구독키는 Azure Portal의 음성 서비스 항목을 선택한 뒤 목록의 키 및 엔드포인트를 클릭하면 확인할 수 있습니다.
(3) 1개 이상의 프로필 등록용 음성 파일과 검증용 음성 파일 1개를 준비합니다. 형식은 .wav이며 특정 텍스트를 포함할 필요가 없습니다. 등록용 음성 파일은 20초 이상이어야 하며 검증용 음성파일은 4초 이상이어야 합니다. 이번 과정에서는 프로필을 등록하기 위해 20대 여성의 음성파일 1개, 30대 여성의 음성 파일 1개, 50대 남성의 음성 파일 1개, 총 3개의 음성 파일을 사용하였습니다.
음성 프로필 생성
(4) 음성을 등록할 프로필을 생성합니다.
1
2
3
4
5
6
7
8
9
10
11
12
def create_profile(sub_key):
header = {'Content-Type': 'application/json', 'Ocp-Apim-Subscription-Key': sub_key}
locale = json.dumps({'locale': 'en-us'})
r = requests.post(main_url, headers=header, data=locale)
global profile_url, profile_ids
profile_id = r.json()['profileId']
profile_url = main_url + profile_id
profile_ids.append(profile_id)
return r.json()
create_profile(sub_key)
프로필을 생성하고 나면 기존에 사용한 URL 끝에 프로필 ID를 추가하여 해당 프로필에 접속하기 때문에 프로필을 생성하는 것과 동시에 Json에서 프로필ID를 추출하여 새로운 URL을 선언해주었습니다. 동일한 방법으로 총 3개의 프로필을 생성할 예정이므로 구분할 수 있도록 프로필 ID를 앞서 생성했던 리스트에 담았습니다.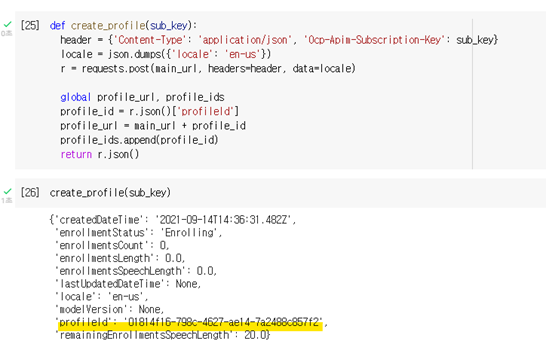
새롭게 생성된 URL은 아래처럼 확인할 수 있습니다.
리스트에 프로필 ID가 제대로 담긴 것도 확인할 수 있습니다.
음성 프로필 등록
(5) 음성 프로필에 기준이 될 음성을 등록합니다. 20초 이상의 음성이어야 하며 암호를 포함할 필요가 없습니다.
1
2
3
4
5
6
7
8
def enroll(sub_key, file_path):
enroll_url = profile_url + '/enrollments'
header = {'Content-Type': 'audio/wav; codecs=audio/pcm; samplerate=16000', 'Ocp-Apim-Subscription-Key': sub_key}
data = open(file_path, 'rb') # 요구하는 파일 형태가 binary이므로 rb 모드를 사용해야 요청 가능
r = requests.post(enroll_url, headers=header, data=data)
return r.json()
enroll(sub_key, r'Identification20f.wav')
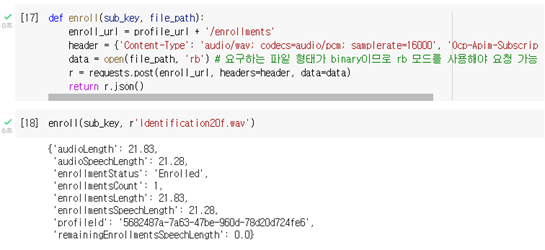
등록하고 나면 Json을 통해 관련 정보를 확인할 수 있으며 20초에서 시간이 모자라는 경우 남은 시간이 표시됩니다. 20초가 모두 등록되면 Enrolled로 바뀝니다. 동일한 방법으로 3개의 프로필을 모두 등록합니다.
음성 식별
(6) 세개의 프로필이 모두 등록되었다면 검증 파일로 식별을 진행합니다. 프로필 ID는 쉼표(,)로 구분하여 모두 작성합니다.
1
2
3
4
5
6
7
8
9
def identify(sub_key, file_path):
id_urls = ','.join(profile_ids)
identify_url = main_url + '/identifySingleSpeaker?profileIds=' + id_urls
header = {'Content-Type': 'audio/wav; codecs=audio/pcm; samplerate=16000', 'Ocp-Apim-Subscription-Key': sub_key}
data = open(file_path, 'rb')
r = requests.post(identify_url, headers=header, data=data)
return r.json()
identify(sub_key, r"Identification.wav")
Json으로 검증 결과를 확인할 수 있으며 가장 유사한 프로필의 ID를 표시합니다. 0에서 1사이로 표시되는 유사도도 확인할 수 있습니다. 각 프로필 별로 유사한 정도에 따라 순위로도 나타냅니다. 30대 여성의 아이디로 식별을 진행했는데 해당 아이디의 유사도가 0.74로 제대로 식별되었습니다.
음성 프로필 삭제
(7) 모든 작업이 끝났다면 음성 프로필을 삭제합니다. 삭제할 경우 Json값을 반환하지 않으므로 HTTP 연결 상태로 성공 여부를 확인합니다.
1
2
3
4
5
6
def delete_profile(sub_key):
header = {'Ocp-Apim-Subscription-Key': sub_key}
r = requests.delete(profile_url, headers=header)
return r.status_code
delete_profile(sub_key)