
[Project][대학원] Future Frame Prediction 모델 개선 프로젝트
Future Frame Prediction 모델 개선 프로젝트
프로젝트 개요

기간
2023.11.1~2023.12.3
설명
연세대학교 공학대학원 컴퓨터소프트웨어 전공 강의인 ‘딥러닝기반 이상탐지모델링’의 팀 프로젝트로 딥러닝 이상탐지 방법론 중 하나인 Future Frame Prediction 모델을 Baseline 논문으로 하여 성능 개선 실험 진행
인원
5명
담당 역할 및 사용 기술
논문 구현 및 개선 Pytorch, Tensorboard, Transformer (ViViT)
저장소
https://github.com/younginshin115/Anomaly_Prediction
Baseline 논문
Future Frame Prediction for Anomaly Detection – A New Baseline.
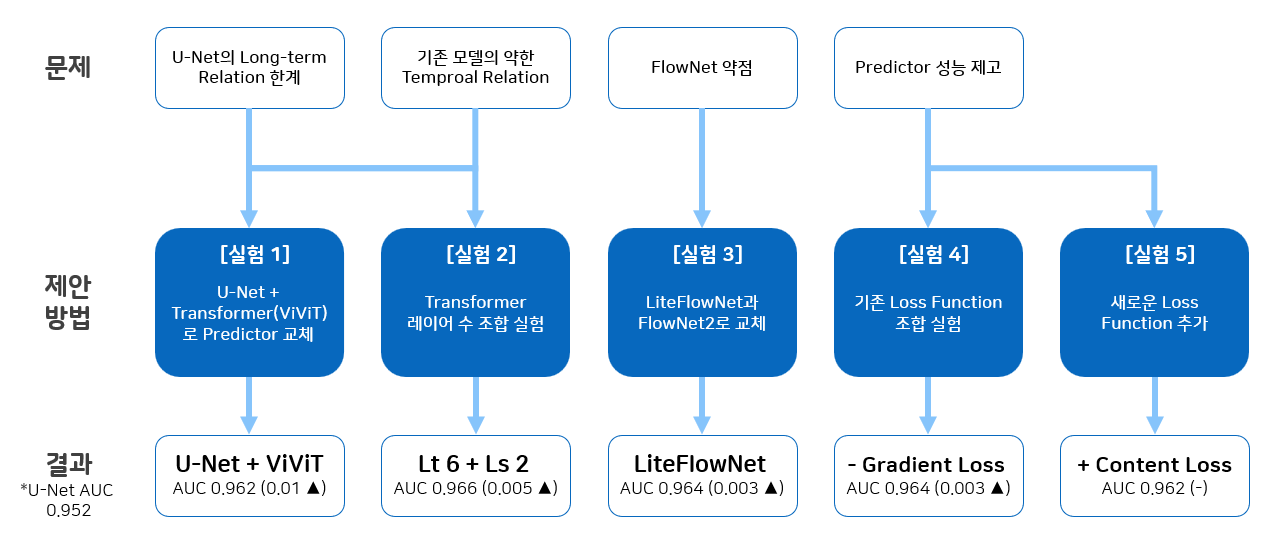
문제 정의 및 방법 제안
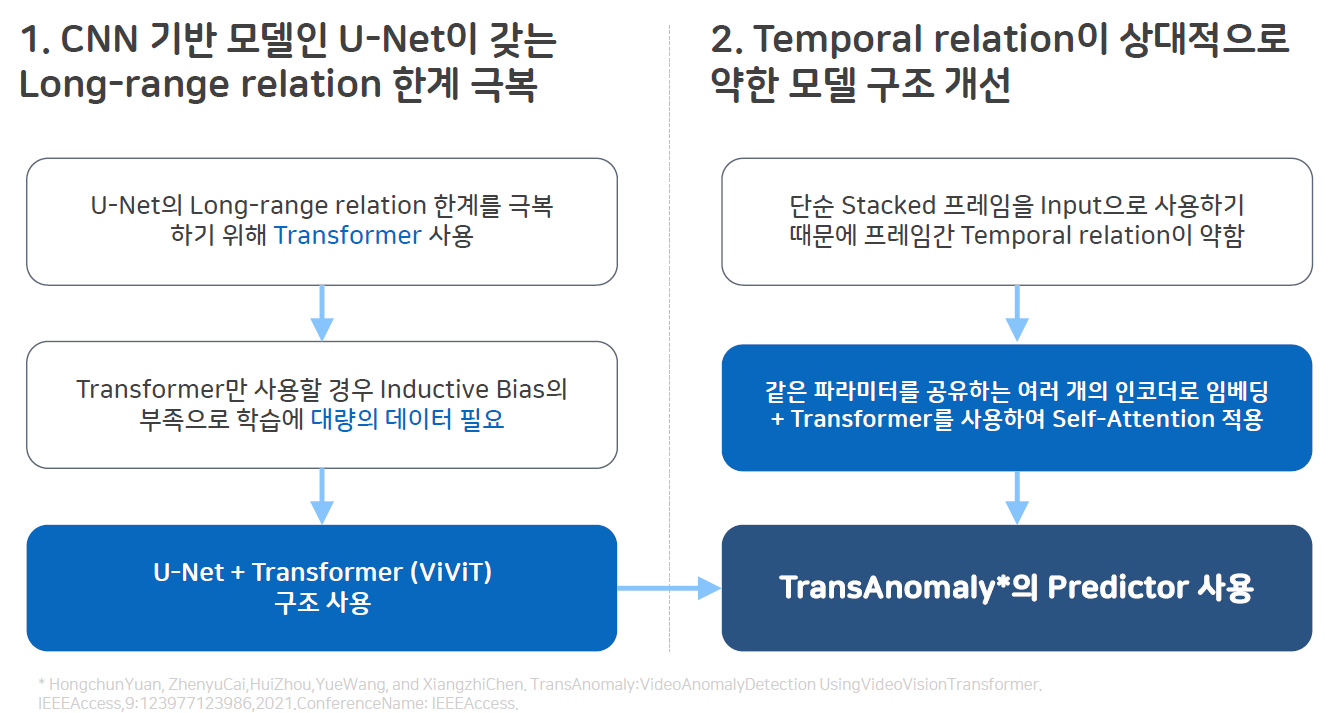
첫번째로 CNN 기반 모델인 U-Net이 갖는 Long-range Relation 한계를 극복하기 위해 Transformer를 사용하고 했습니다. 하지만 Transformer를 단독으로 사용할 경우 Inductive Bias가 부족해서 학습에 대량의 데이터가 필요하다는 단점이 있었습니다. 이를 극복하기 위해 Transformer를 단독으로 사용하지 않고 U-Net과 Transformer를 결합한 형태의 구조를 사용하여 U-Net의 장점과 Transformer의 단점을 모두 취하고자 했습니다.
두번째로 모델 구조를 분석하여 현재 Baseline 논문인 Future Frame Prediction 모델의 경우 프레임을 단순 합하여 사용하기 때문에 Temproal Relation이 약하다는 문제가 있습니다. 이에 같은 파라미터를 공유하는 여러개의 인코더로 임베딩 추출하고 Transformer를 사용하여 Self-Attention을 적용하는 것으로 이 문제를 해결하고자 했습니다.
이 두가지를 모두 고려하였을 때 Predictor의 구조를 기존에 발표되었던 TransAnomaly의 Predictor의 구조로 교체하면 두가지 문제를 모두 해결할 수 있을것이라고 생각했습니다.
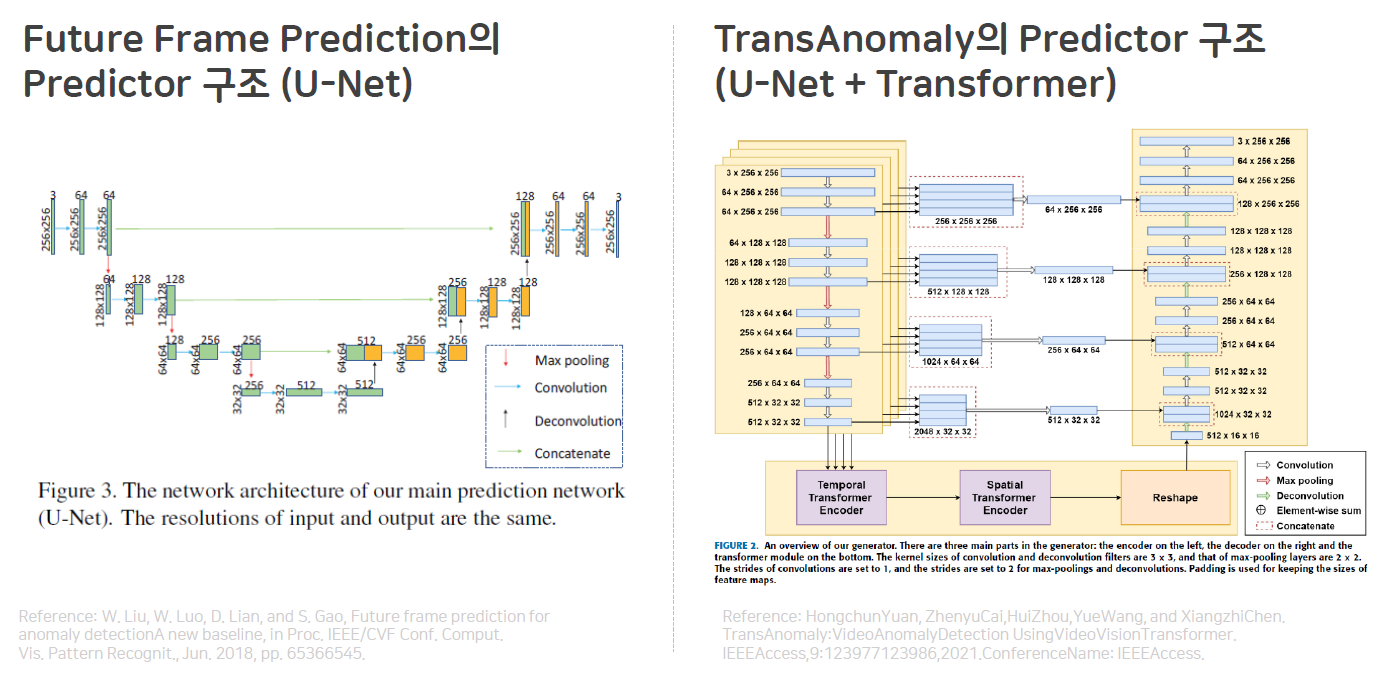
두번째를 좀 더 설명하기 위해 Future Frame Prediction과 Transanomaly의 Predictor 구조를 가져왔습니다. 보시는 바와 같이 U-Net은 input이 하나입니다. 모든 프레임을 쌓아서 넣기 때문에 서로에 대한 Temporal Relation이 약하다는 단점이 있습니다. 반면 TransAnomaly의 Predictor 구조를 보시면 인코더를 4개의 레이어를 병렬로 사용하여 4개의 feature를 뽑고 이를 순서 정보를 지켜서 Transformer로 인코딩을 하므로 시간적, 순서적 정보가 상대적으로 잘 살아있다는 장점이 있습니다.
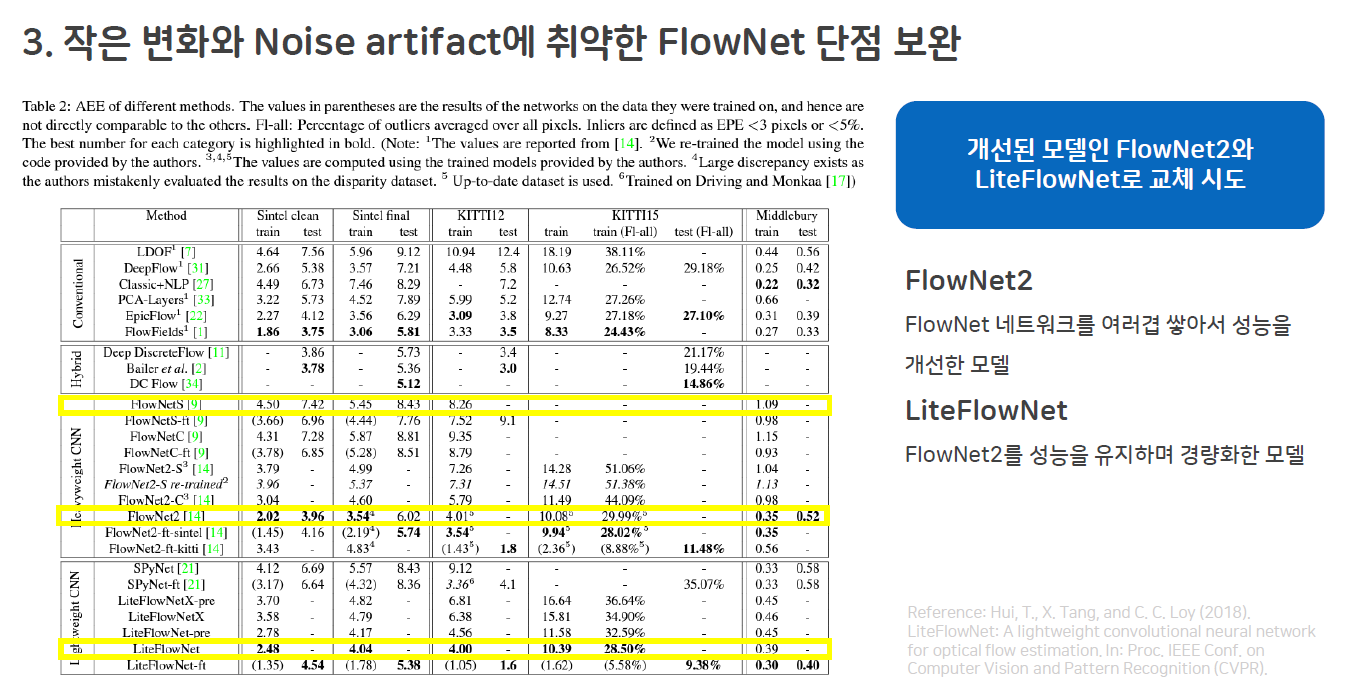
Future Frame Prediction 모델은 Temporal 정보를 확보하기 위해 실제 프레임과 그 직전 프레임과의 움직임 차이, 예측한 프레임과 그 직전 실제 프레임과의 움직임 차이를 Optical Flow 모델을 이용하여 계산합니다. Baseline 모델은 FlowNet을 Optical Flow 모델로 사용했습니다. 하지만 이 FlowNet은 초기 모델인 만큼 작은 변화와 Noise Artifact에 취약해 현실에 적용하기 어렵다는 단점이 있었습니다. Baseline 논문이 발표된 이후 FlowNet에 대한 후속 연구가 이어져 FlowNet2, LiteFlowNet 등 다양한 개선 모델이 나왔습니다. 이에 FlowNet을 FlowNet2와 LiteFlowNet 교체했습니다.

Future Frame Prediction은 모델의 성능이 Predictor의 성능에 달려있다고 강조하고 있습니다. 이에 기존 Loss Function의 조합을 현재의 모델 구조에서 테스트하여 최적의 Loss Function 조합을 찾고 새로운 Loss Function을 추가하는 실험을 진행했습니다.
실험 결과
실험 공통 개요
| Dataset | UCSD Pedestrian 2 (ped2) |
| Iteration | 10,000 |
| Validation Interval | 1,000 |
| Dataset Preprocessing | 256x256으로 리사이징, 모든 프레임의 픽셀 intensity는 [-1,1]로 정규화 |
| 예측에 사용할 프레임 개수 | 4 |
| Optimizer | Adam |
| Activation | ReLU |
대부분은 Baseline 논문의 실험 방식을 따랐습니다. Iteration의 경우 시간적, 자원적 제약의 한계로 한 실험당 10,000번만 진행했습니다.
실험 공통 목적
앞서 언급한 것 처럼 모델의 성능은 Predictor의 성능에 달려있습니다. 실험의 공통적인 목적은 다양한 Loss 함수로 Predictor를 학습하여 정상 상황의 Future Frame을 높은 성능으로 예측하는 Predictor를 구현하고 이 Predictor로 이상 상황을 잘 탐지해내는 것입니다.
아래 이미지는 저희 모델이 Avenue 데이터셋읠 학습할 때 중간 저장한 이미지입니다. 각 두 이미지 중 왼쪽이 저희가 예측한 이미지이고 오른쪽이 실제 이미지입니다.

학습을 막 시작했을 때, 즉 Iteration이 천번 이하일 때는 보시다시피 이미지가 잘 예측되지 않는 것을 알 수 있습니다. 하지만 실험이 막바지에 이르렀을 때, 즉 iteration이 9,000번 이상이 됐을 때는 실제와 거의 비슷한 이미지를 예측해내는 것을 볼 수 있습니다. 이처럼 좋은 성능의 Predictor를 만드는 것이 이 실험의 목적입니다.
실험 1 Predictor: U-Net vs U-Net + Transformer (ViViT)
첫번째 실험은 Predictor의 구조를 변경하는 실험입니다. Transformer 모델은 영상 데이터에 많이 사용하는 ViViT: A Video VIsion Transformer를 사용했습니다. 기존의 U-Net 구조에서 U-Net + Transformer 구조로 변경했을 떄 AUC가 상상하는 것을 확인할 수 있었습니다. 이후 실험은 모두 오른쪽의 U-Net + Transformer 구조의 Predictor로 진행되었다는 것을 미리 말씀드립니다.
| U-Net | U-Net + Transformer | |
|---|---|---|
| Best AUC | 0.9515 | 0.9616 |
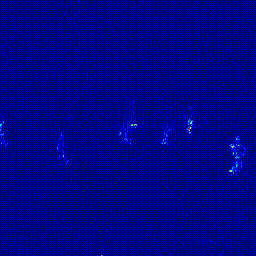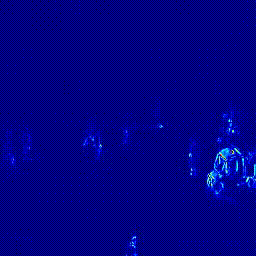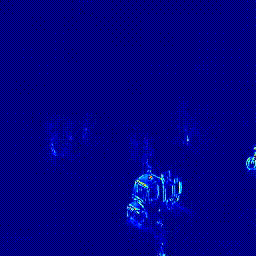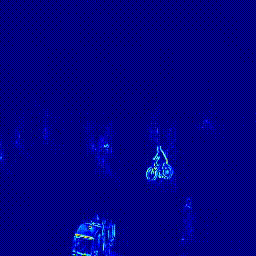
| Heatmap | 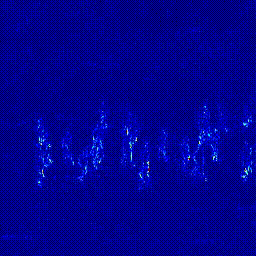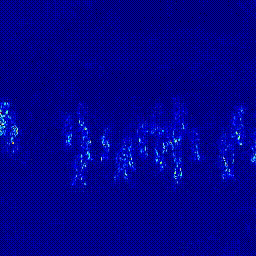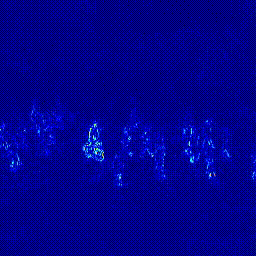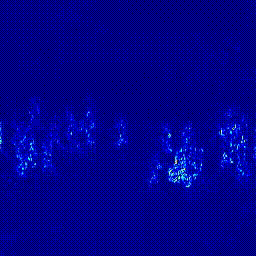 |
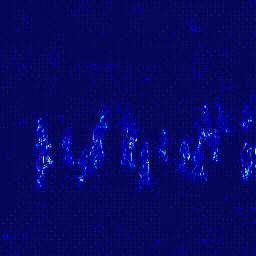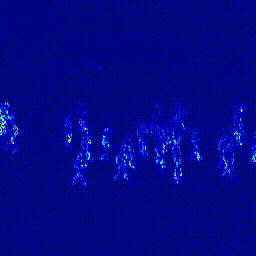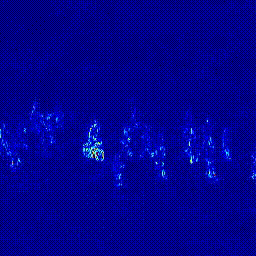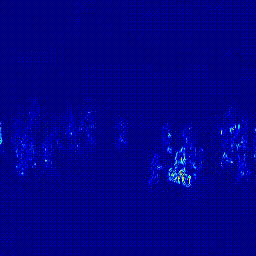 |
*참고: 두 실험은 모두 Optical Flow 모델을 FlowNet2로 하여 실험을 진행하였습니다
실험 2 Transformer Depth: 0~7
두번째 실험은 Transformer의 Depth를 조정하는 실험입니다. Transformer는 여러개의 동이란 구조의 층(Layer)을 쌓아올려 네트워크를 형성할 수 있습니다. Self-Attention Mechanism이 여러 층에서 반복되면서 모델이 입력 시퀀스의 다양한 위치간 상호 작용을 학습하게 됩니다. Depth는 이렇게 쌓아올린 층의 개수를 말합니다. Depth가 깊어질 수록 모델의 표현력이 상승하지만 계산 비용이 증가하거나 과적합, 그래디언트 소실 등의 문제가 발생할 수 있습니다.
아래는 저희 모델의 Predictor 구조입니다. 저희 모델은 Temporal Transformer 인코더와 Spatial Transformer 인코더를 사용하고 있습니다. 즉, 저희가 진행한 Transformer Depth의 실험은 아래의 구조를 몇번 반복하여 인코더를 구성하는지에 대한 문제였습니다.
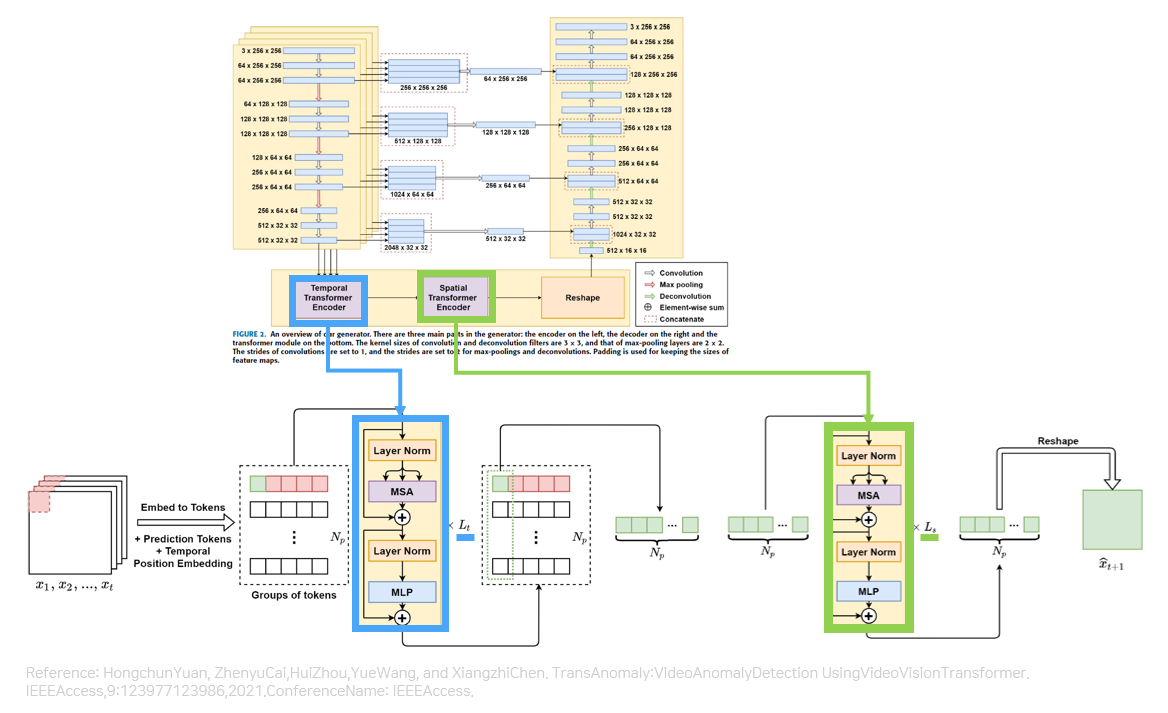
Spatial Depth는 0에서 7사이로 Temporal Depth는 1에서 4사이로 조정하여 실험을 진행하였으며 Spatial Depth가 6, Temporal Depth가 2일때 가장 높은 성능을 보였습니다.
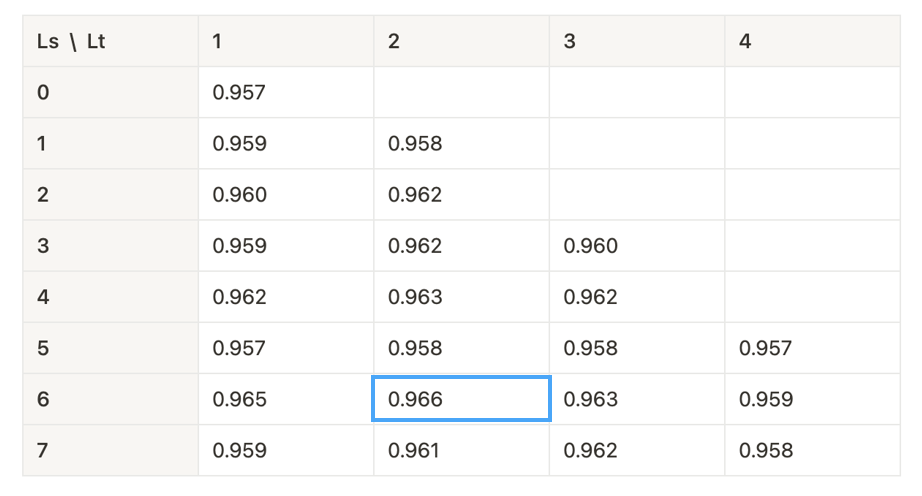
실험 3 Optical Flow: FlowNet2 vs LiteFlowNet
세번째 실험은 Optical Flow 모델 실험입니다. U-Net을 사용한 기본 모델에서는 LiteFlowNet보다 FlowNet2를 사용했을 때가 성능이 더 좋게 나왔지만 저희 모델 구조에서는 LiteFlowNet이 더 높은 성능을 보였습니다.
| U-Net | U-Net + Transformer | |
|---|---|---|
| FlowNet2 | 0.9515 | 0.9616 |
| LiteFlowNet | 0.943 | 0.9647 |
실험 4 기존 Loss Function 검증
네번째 실험은 기존 Loss Function을 검증하는 실험입니다. 기존 Baseline 모델에서 사용한 Loss Function은 아래와 같습니다.

우선 Adversarial Loss는 GAN 구조에서 필수적인 Loss Function이라고 생각해 제외하지 않았습니다. Intensity Loss와 Gradient Loss, Optical Flow Loss를 제외하거나 하나씩 남기면서 실험을 진행하였습니다. 저희 모델 구조에서는 Gradient Loss를 사용하지 않는 편이 더 높은 성능을 보였습니다.

여기서 신기한 점을 하나 발견했습니다. Intensity Loss를 제외하였을 때 성능이 확 떨어지는 모습을 보였다는 것입니다. Baseline 논문에서는 Intensity Loss를 무조건 포함하여 실험을 진행하였는데 저희는 그 이유가 궁금하여 Intensity Loss 또한 실험 대상으로 삼았습니다. 그런데 이렇게 눈에 띄게 성능이 떨어진다는 것이 신기했습니다. 그래서 예측된 이미지를 직접 확인했습니다. Intensity Loss는 프레임간 색상 강도 차이를 최소화하는 Loss Function 입니다. 그렇기 때문에 Intensity Loss를 제외하면 예측 자체가 정상적으로 진행되지 않는 것을 확인할 수 있었습니다. Gradient Loss는 프레임간 경계차이를 최소화하는 Loss Function인데 Intensity Loss가 있다면 경계가 조금 흐려지더라도 Ground Truth에 가깝게 이미지가 재현되는 것을 확인할 수 있었습니다.

실험 5 새로운 Loss Function 추가: Perceptual Loss
마지막 실험은 새로운 Loss Function을 추가하는 실험입니다. 저희는 Perceptual Loss를 추가하고자 했습니다. Perceptual Loss란 Reconstruction 모델에서 많이 사용하는 Loss Functoin으로 Low Level에서 단순히 이미지 차이를 계산하는 Intensity Loss나 Gradient Loss와 달리 실제 시각적으로 유사한지를 확인하는 손실 함수입니다. Perceptual Loss 중에서도 아래 두 Loss Function을 추가하는 실험을 진행하였습니다.

Content Loss의 경우 가중치 1로 적용했을 때 0.9579의 AUC를 보였고 가중치를 0.5로 적용하였을 때는 0.9616의 AUC를 보였습니다. Style Loss는 AUC가 0.9578로 성능이 개선되지 않아 최종 실험에 포함하지 않았습니다.
| U-Net | U-Net + Transformer | |
|---|---|---|
| Best AUC | 0.9579(가중치 1) 0.9616(가중치 0.5) |
0.9578 |
| Heatmap | 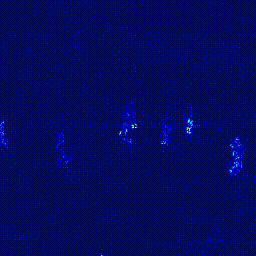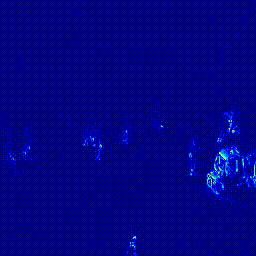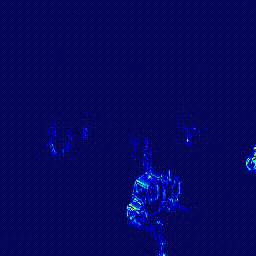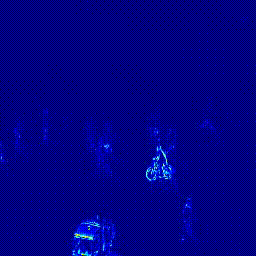 |
 |
최종 실험
모든 실험의 결과를 조합한 최종 실험의 결과입니다. 성능 증가를 확인할 수 있었고 AUC 그래프가 우상향하고 있었으므로 Iteration을 좀더 진행할 경우 성능이 더 향상할 수 있을 것이라고 생각합니다. 이에 Predictor의 성능을 개선하여 모델 성능이 유의미하게 개선되었음을 확인할 수 있었습니다.
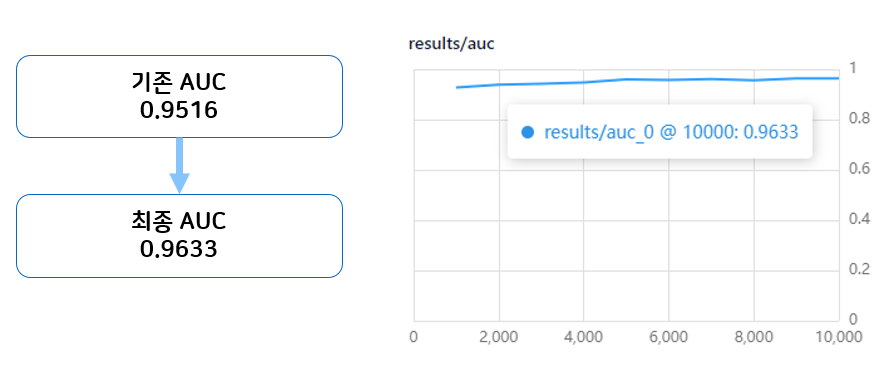
추가 논의점
- 1개월간 진행되는 학교 수업의 과제로 시간적, 자원적 한계가 있어 Iteration을 1만 번으로 제한하여 실험을 진행했습니다. 최종 실험의 경우 그래프가 우상향 하고 있었으므로 Iteration 수를 늘려 실험을 진행한다면 다른 Insight를 얻을 수 있을 것으로 예상합니다.
- ViVit의 경우 U-Net의 Locality 한계를 보완하는 역할을 하기 때문에 여러 데이터셋이 혼재된 경우에 더 강하다는 특징을 가집니다. 추후 여러 데이터셋으로 추가 학습하여 성능을 볼 수 있으면 좋겠습니다.
- Style Loss나 Content Loss의 경우 가중치 조정, 최적화를 통해 성능을 높일 수 있는 가능성이 있습니다.
결론
저는 데이터 엔지니어로 데이터 분석이 제 주 업무는 아니지만 이번 프로젝트를 통해서 데이터 분석 설계부터 결과 분석까지 쭉 경험하면서 다음 두가지를 얻을 수 있었습니다. 첫번째는 데이터 분석에 대한 이해도가 높아지면서 데이터 분석가와의 협업이 좀더 원활해 질 것으로 기대합니다. 두번째로 데이터 파이프라인을 구축할 때 좀더 데이터 분석 친화적으로 구축할 수 있을 것 같습니다.
감사합니다.