
[Project] 채팅 메시지 분석 ML-Bot ‘JAVAS’ 개발 프로젝트
채팅 메시지 분석 ML-Bot ‘JAVAS’ 개발
프로젝트 개요
기간
2021.6.7~2021.8.17
인원
6명
설명
머신러닝 기반 챗봇 ‘JAVAS’를 개발하는 프로젝트입니다. 라이브 방송의 채팅 메시지를 실시간으로 머신러닝 분석하여 비속어 필터링, 긍/부정 감정 분석, 단어 빈도순 워드 클라우드, 원본 데이터 DB 저장 기능을 제공합니다.
서비스 소개
지원하는 채널인 Youtube, Twitch, 네이버 쇼핑라이브 중 원하는 채널을 선택하고 방송의 URL을 입력하면 4가지 서비스를 제공합니다.

1. 비속어 탐지 및 필터링
머신러닝으로 채팅 메시지를 분석해 자동으로 필터링합니다. 원하는 경우 토글 버튼을 눌러 원본 채팅을 확인할 수 있습니다. 우측 하단의 대시보드 버튼을 클릭하면 분당 비속어 개수를 확인할 수 있습니다.
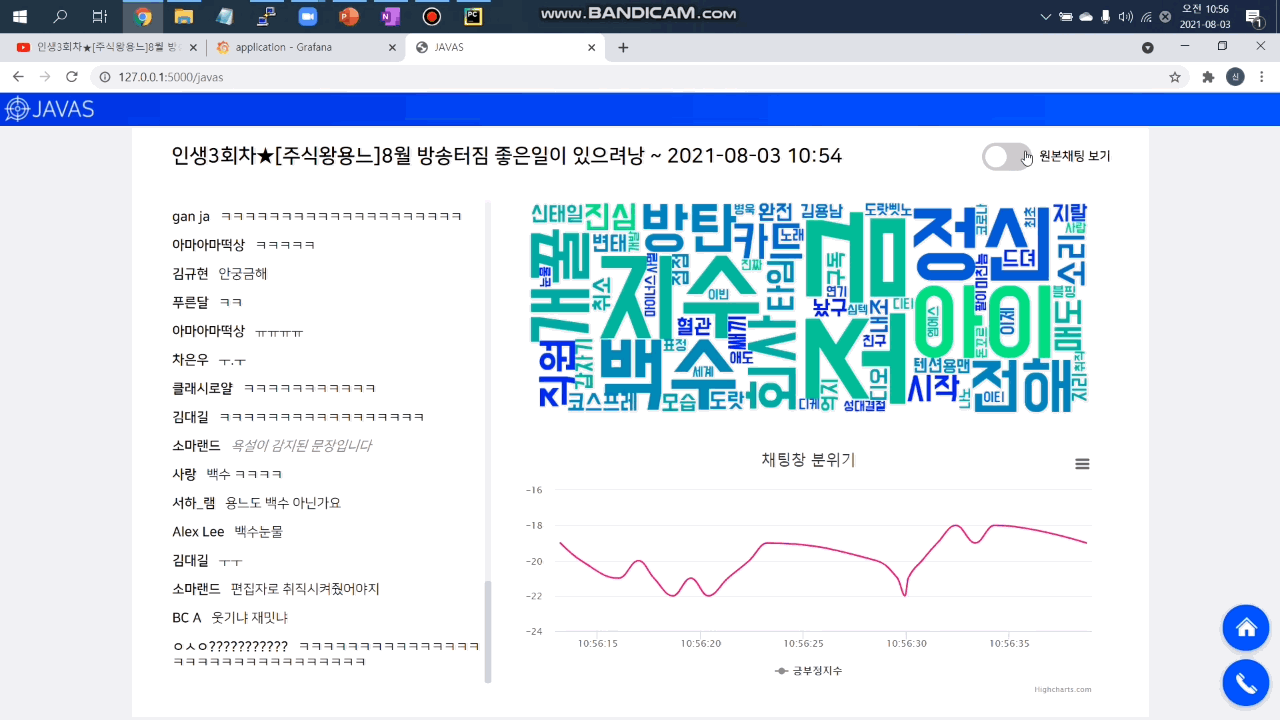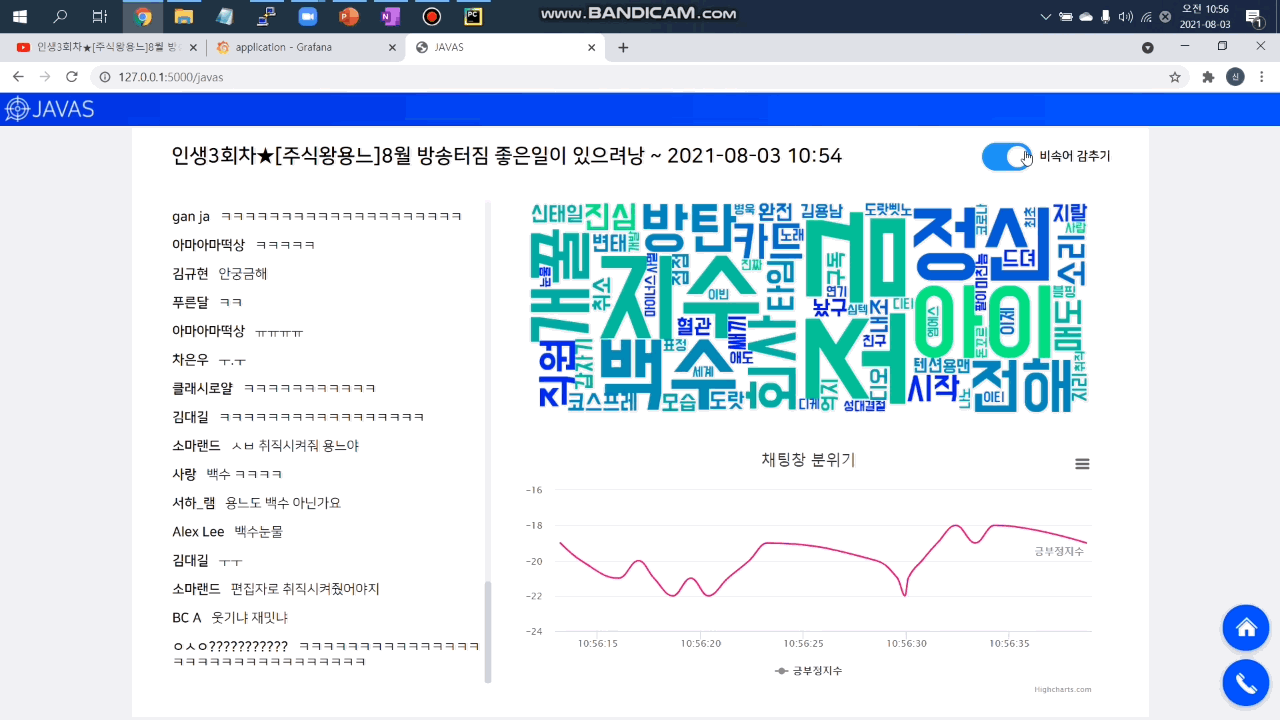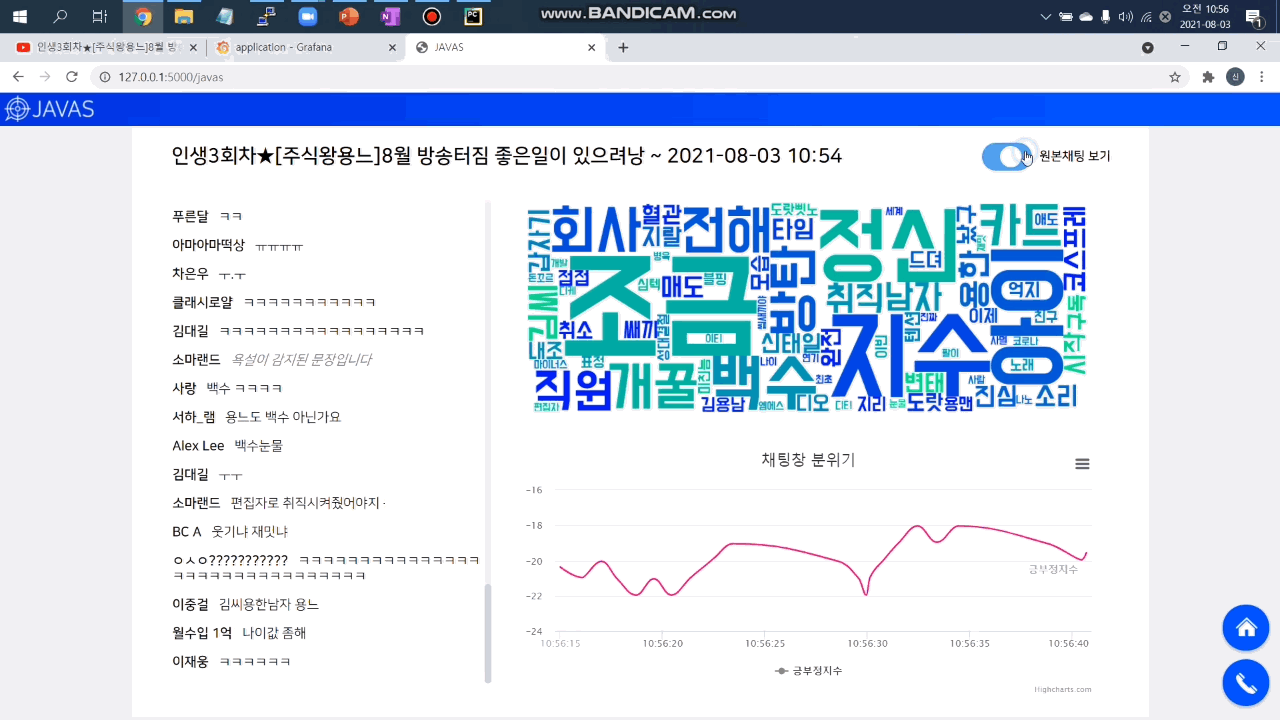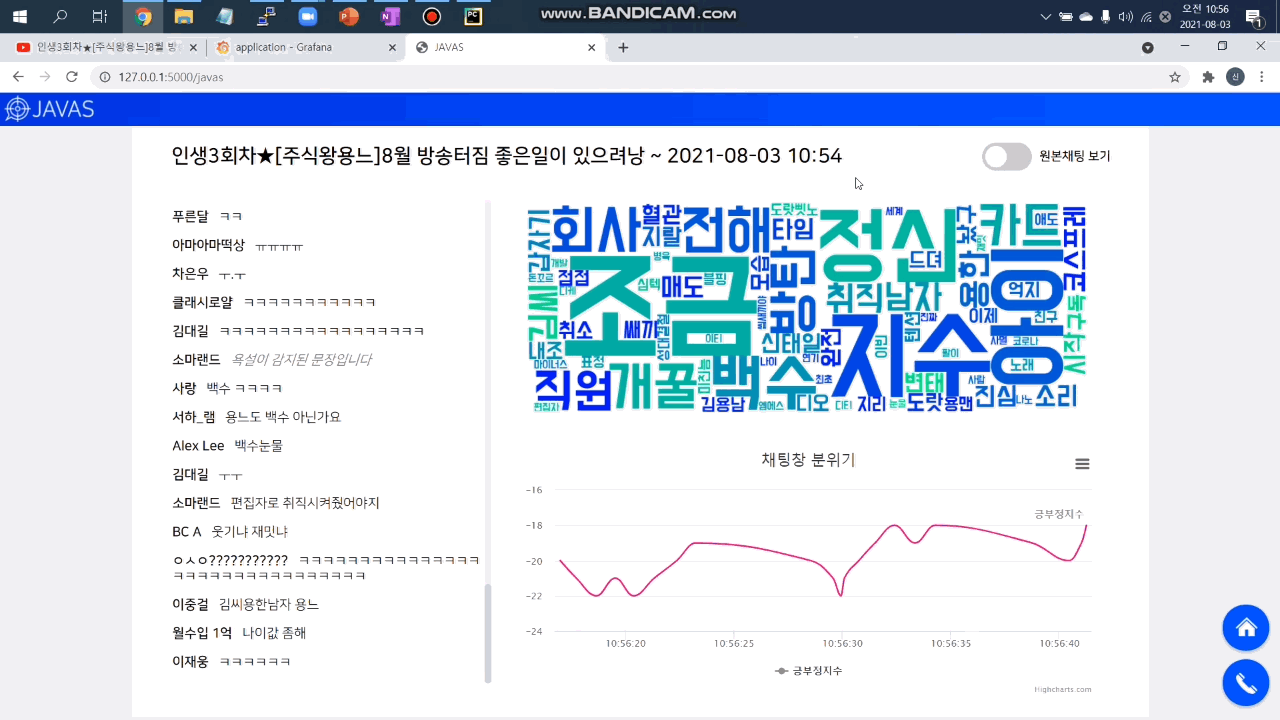
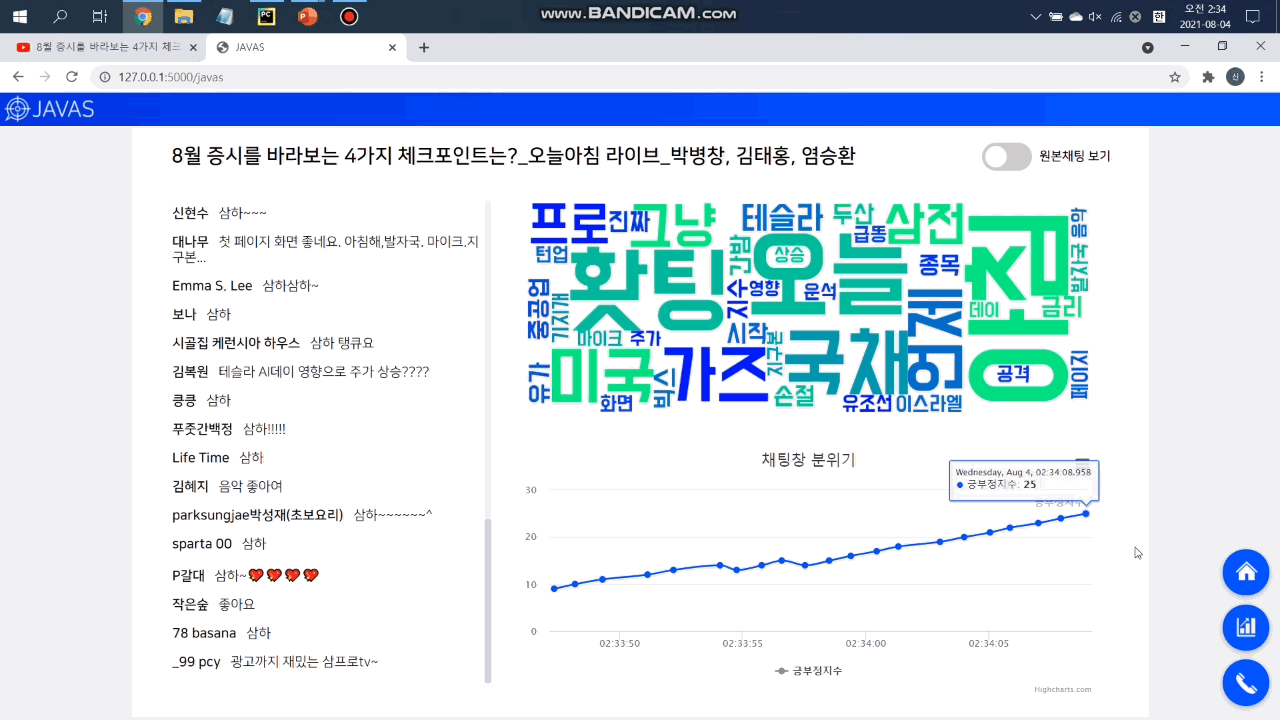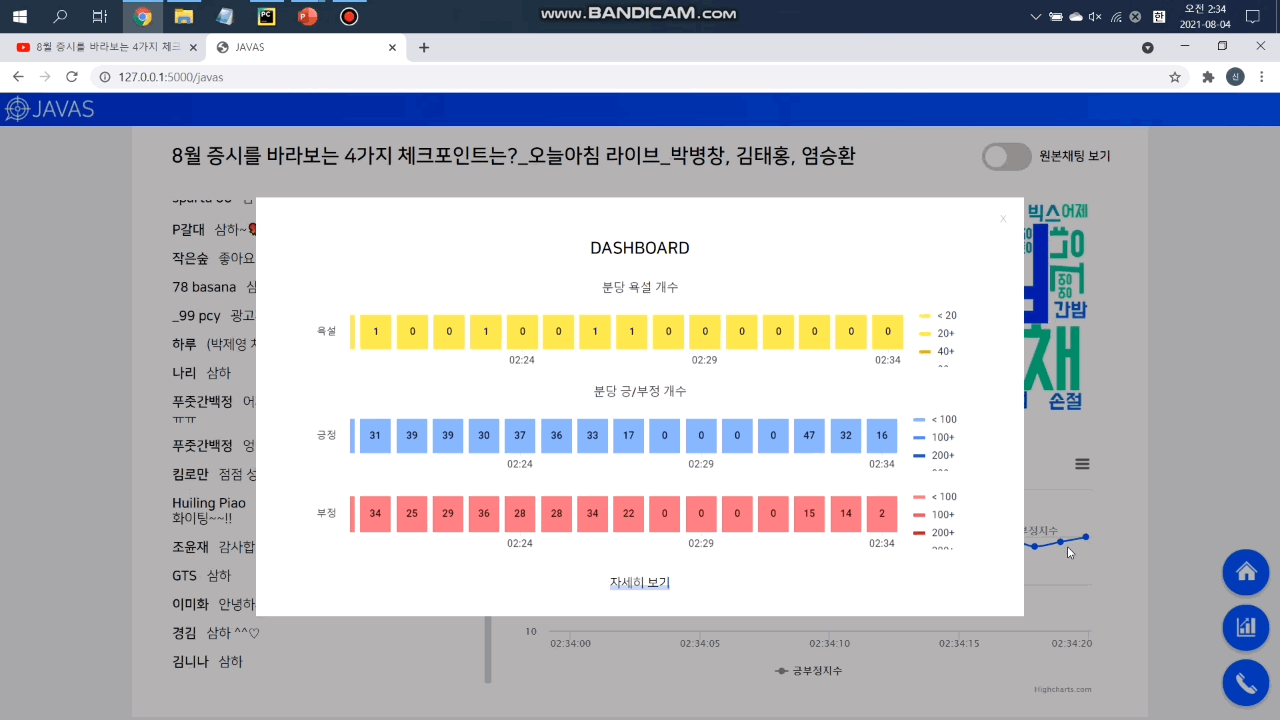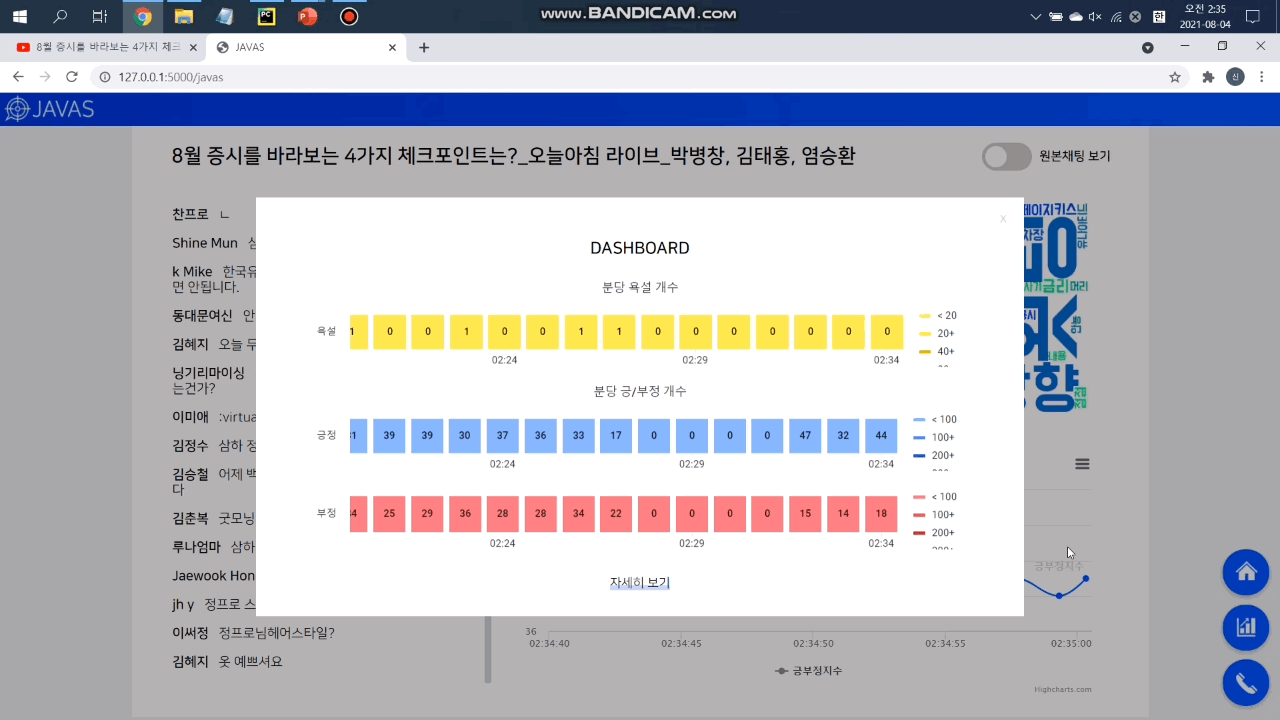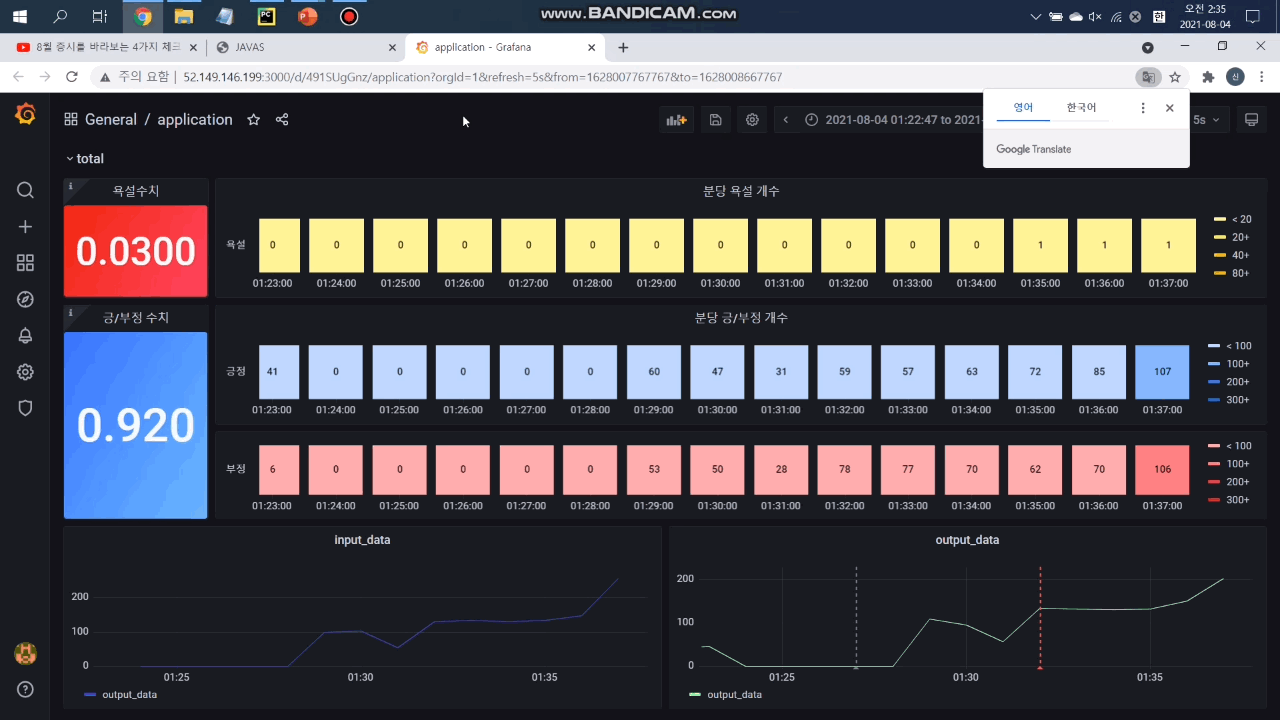
2. 감정 분석 및 시각화 대시보드
머신러닝으로 채팅 메시지를 분석해 채팅별 긍/부정 지수를 예측합니다. 채팅창 우측 하단에서 긍/부정 방향성을 확인할 수 있고 우측 하단의 대시보드 버튼을 클릭하면 분당 긍/부정 채팅 개수를 확인할 수 있습니다. 아래 자세히 보기 버튼을 클릭하면 더 자세한 정보를 확인할 수 있는 그라파나 대시보드로 이동합니다.
3. 워드 클라우드
라이브 방송 진행자가 채팅창의 핵심 키워드를 바로 파악할 수 있도록 빈도순 워드 클라우드를 제공합니다.
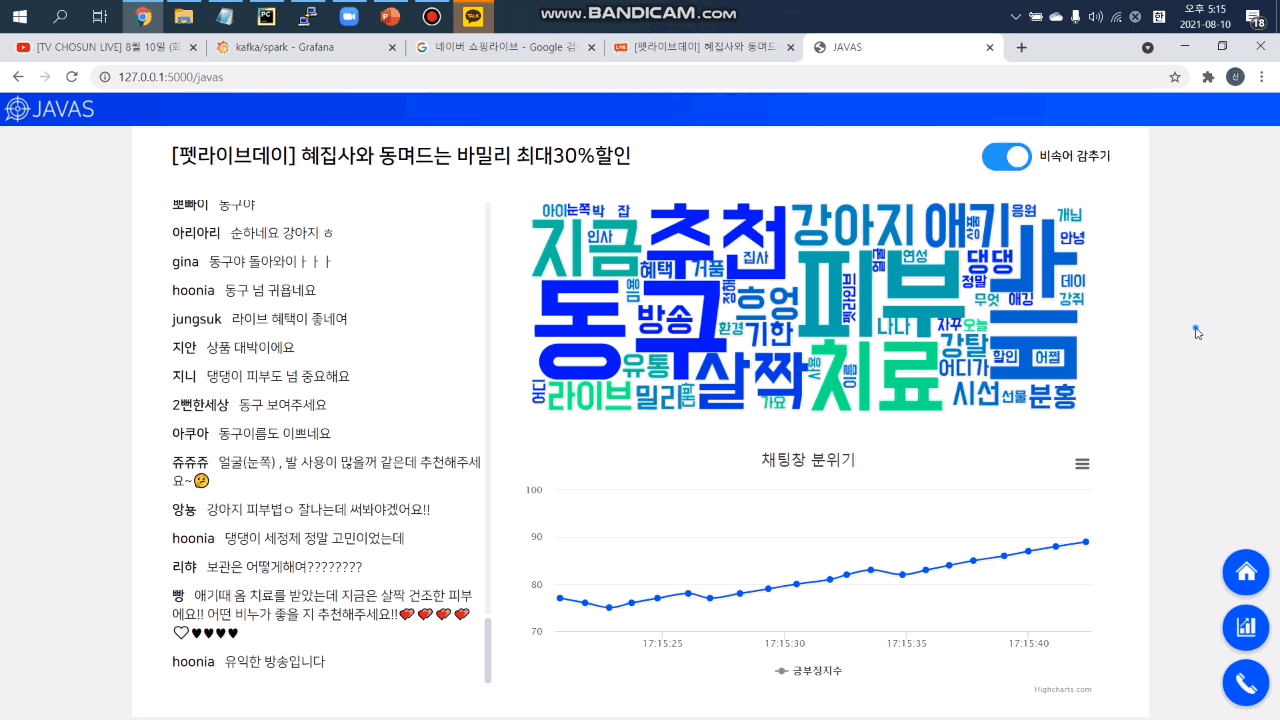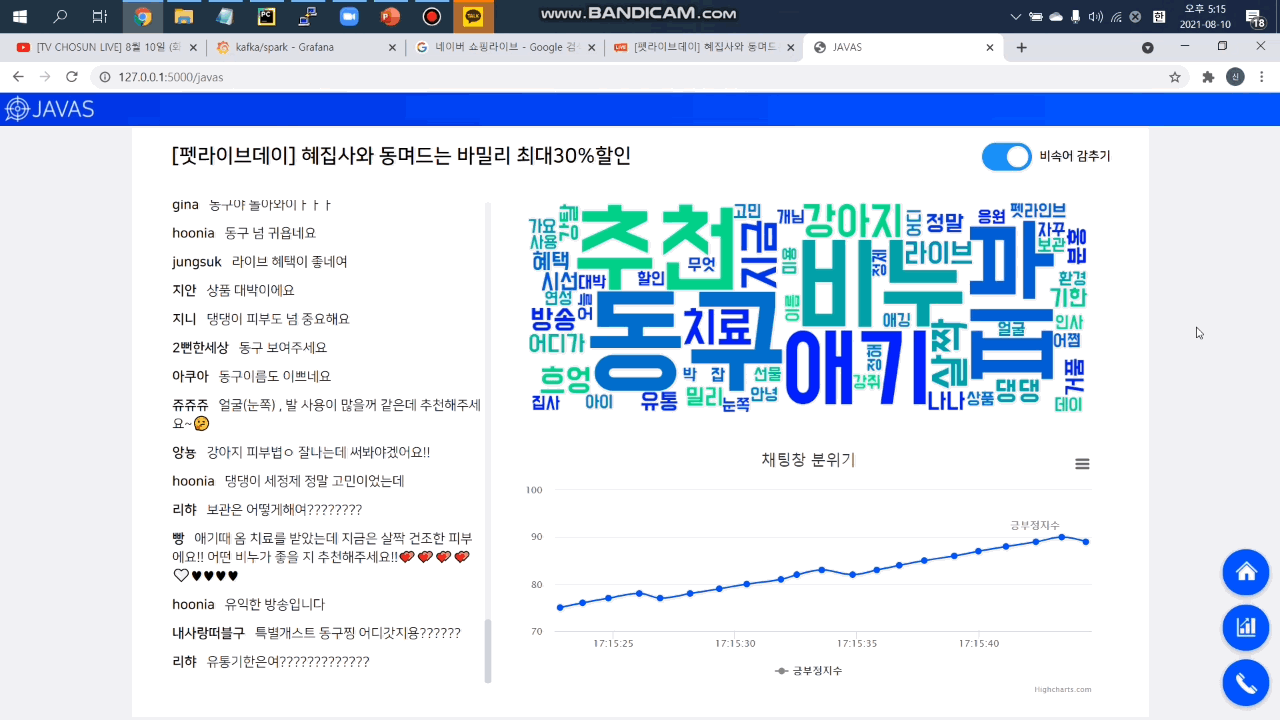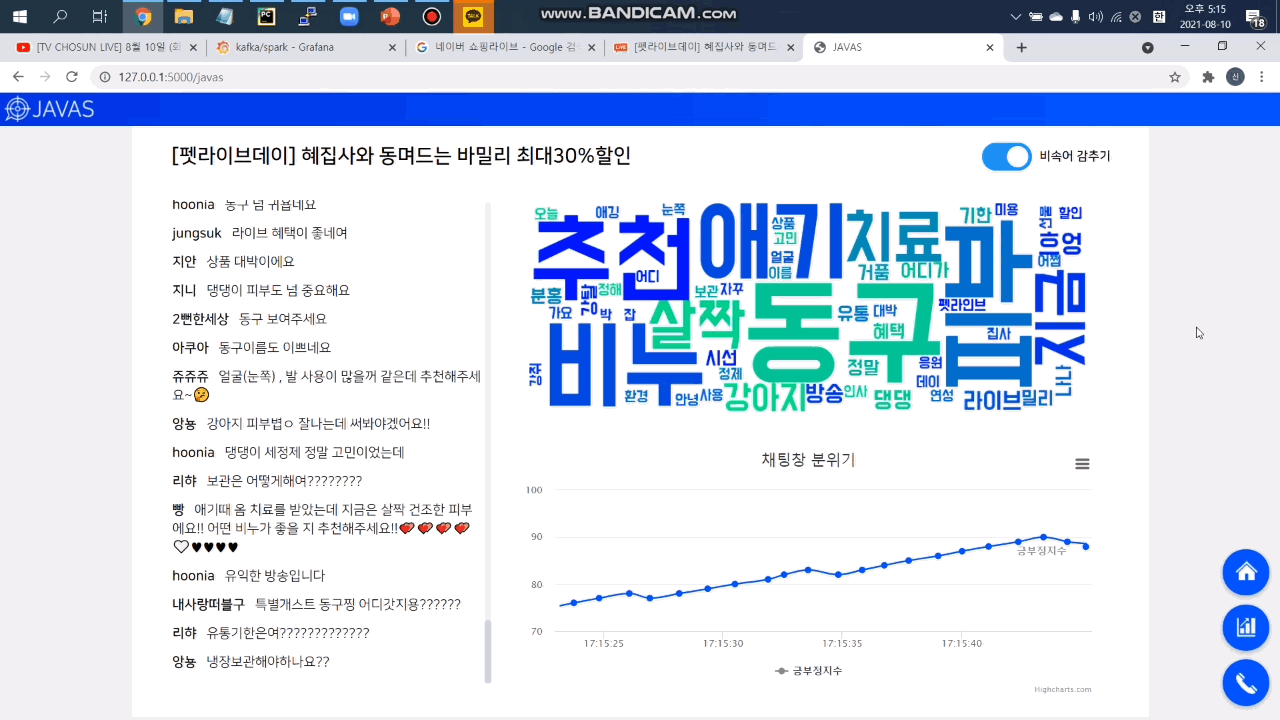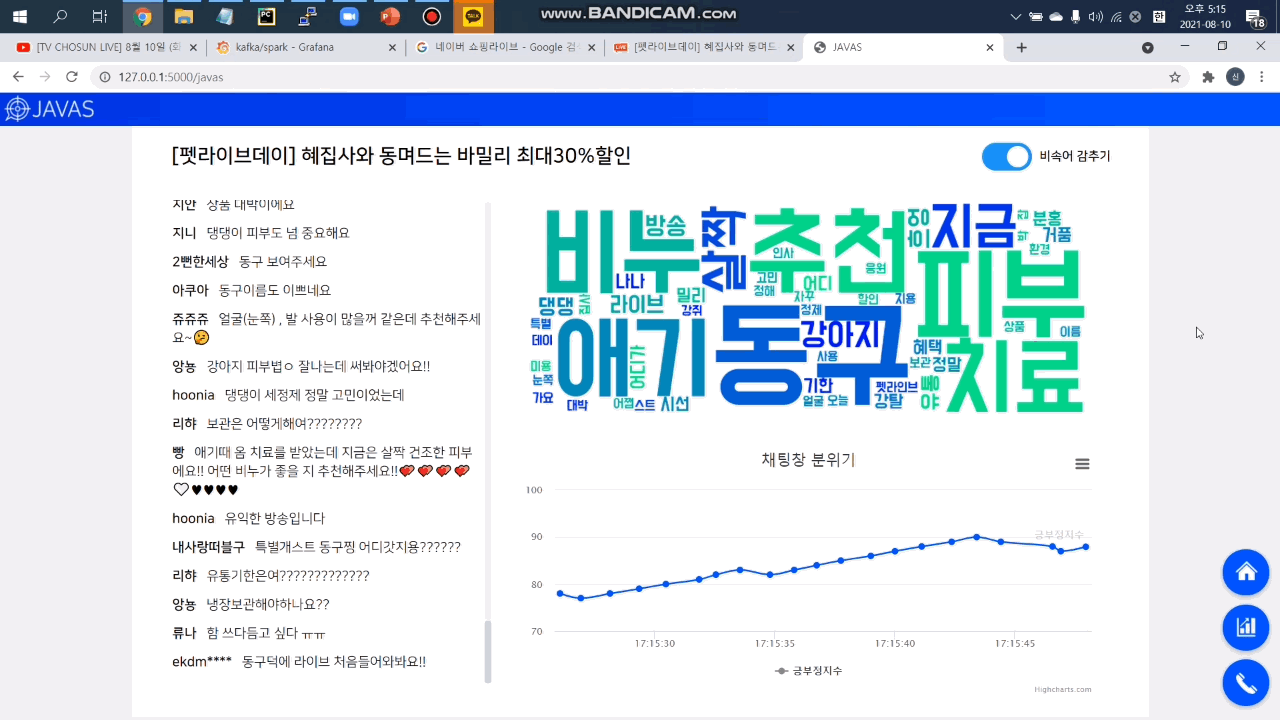
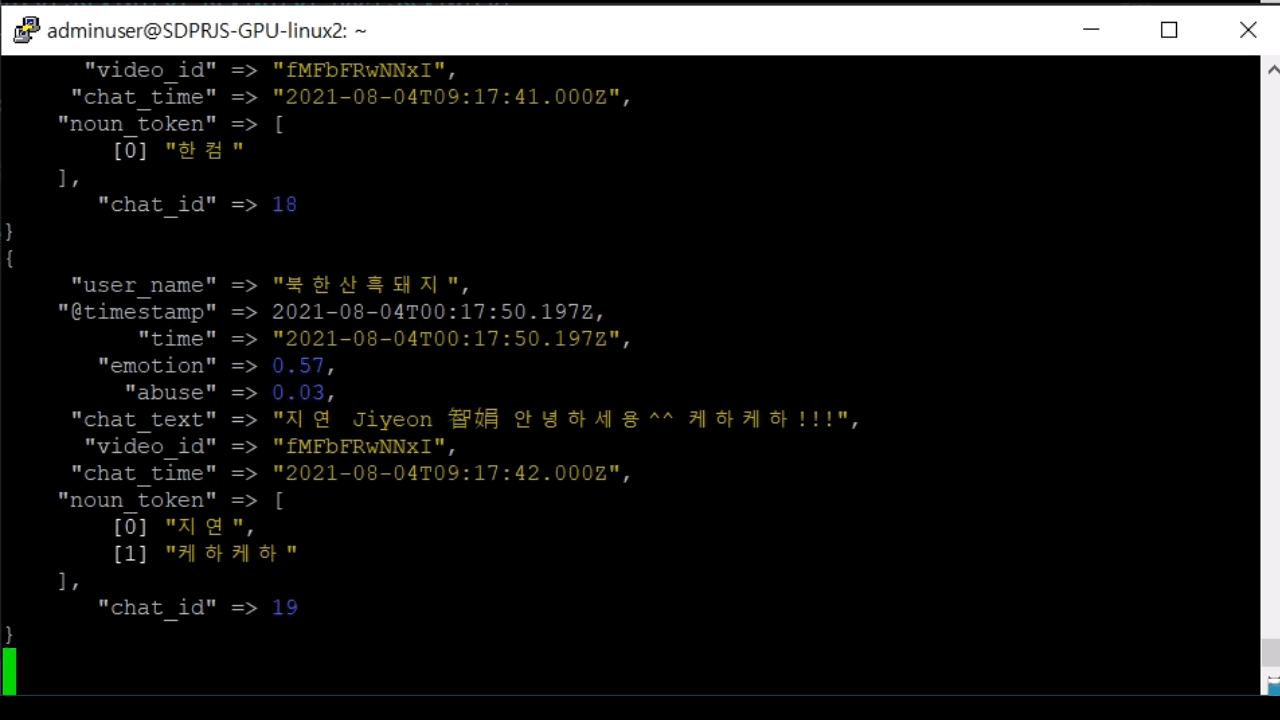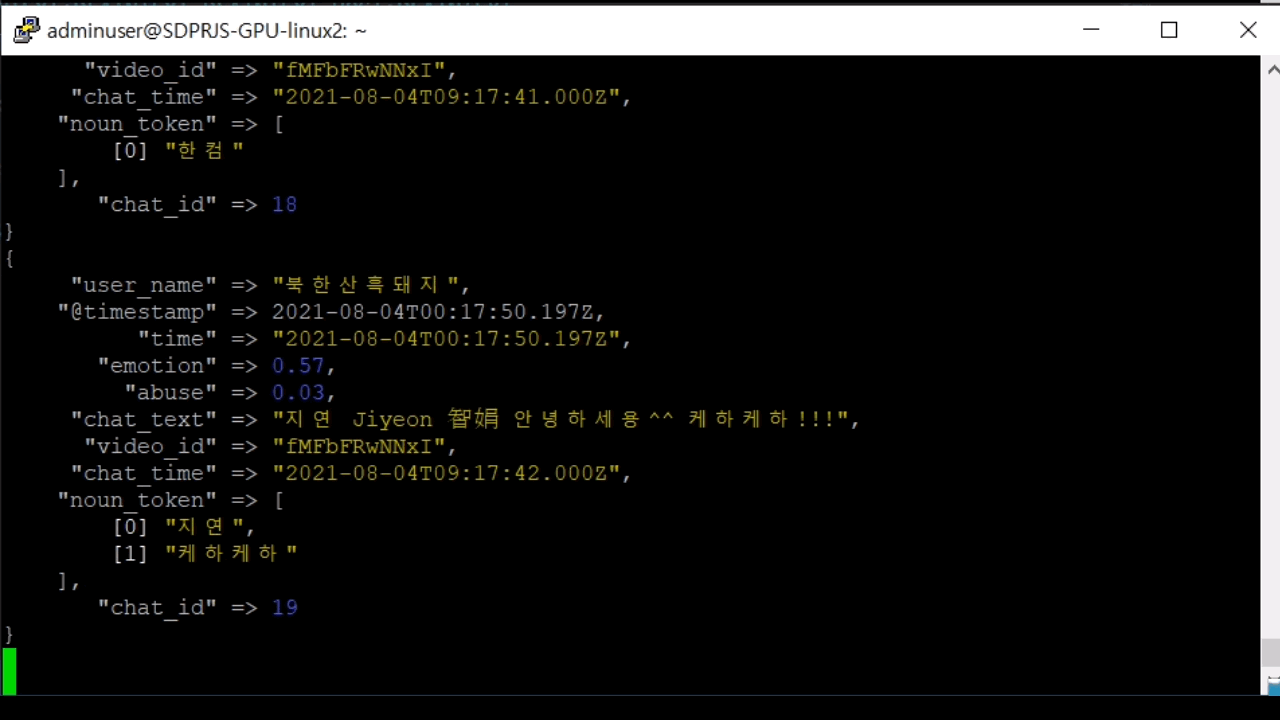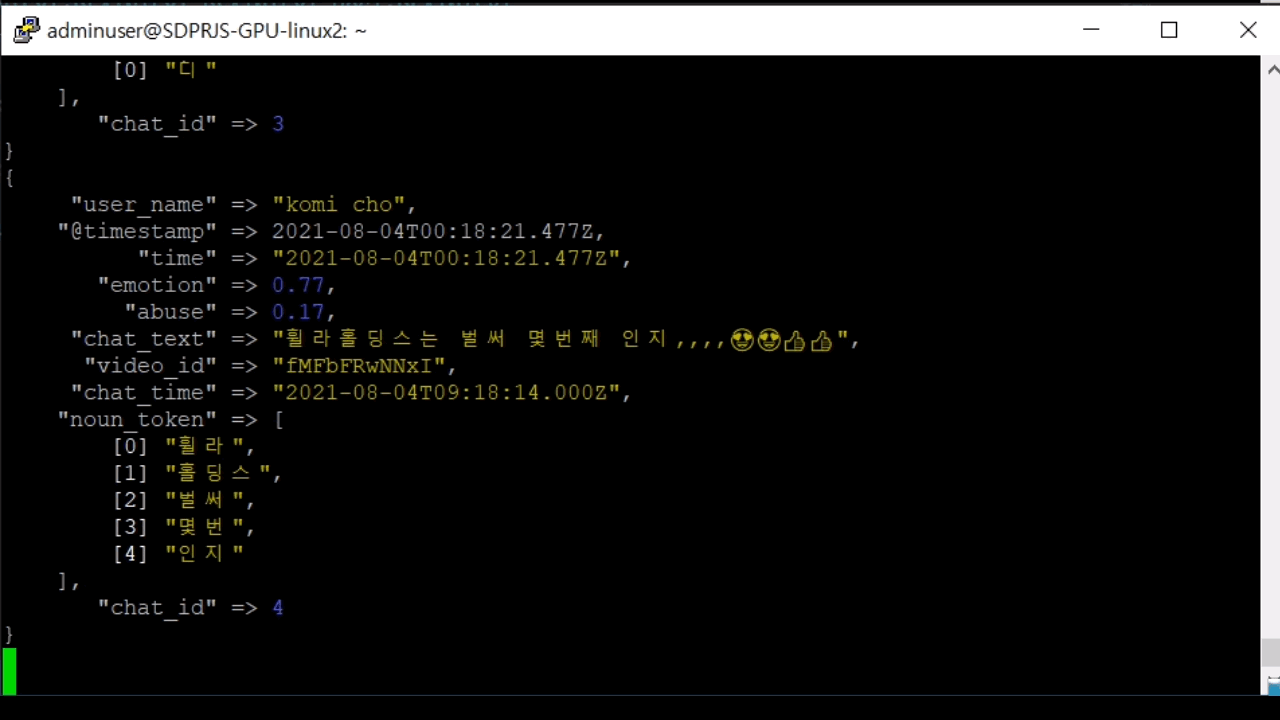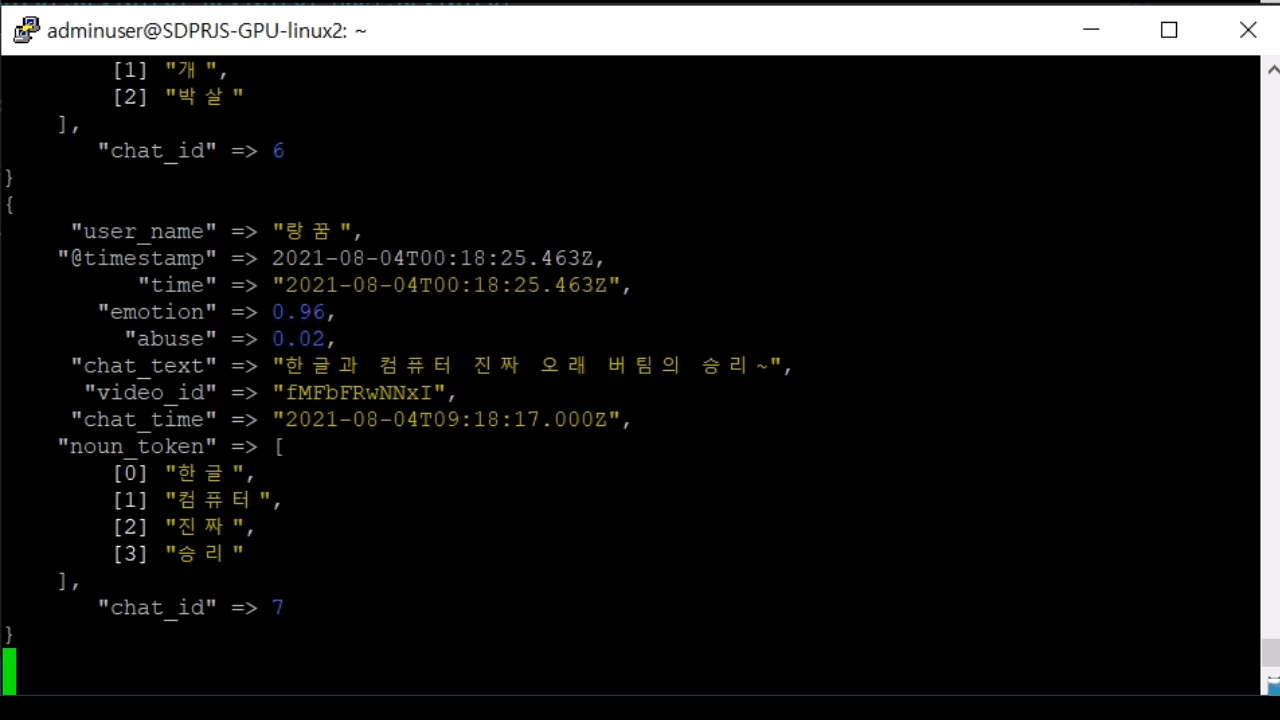
4. 원본 채팅 저장
방송 식별자, 채팅 작성자, 채팅 작성 시간, 채팅 내용, 비속어 포함 여부 등을 실시간으로 DB에 저장합니다. 추후 방송 진행자가 채팅 방송 종료후 채팅 내용을 확인하거나 일정 횟수 이상 비속어를 사용한 이용자를 제재하는 등 여러가지 목적으로 사용할 수 있습니다.
5. 그외 기능
- 어떤 플랫폼에서 라이브 방송을 하더라도 JAVAS를 사용할 수 있도록 스크레이핑 방식을 사용했습니다. 현재 지원하는 채널은 Youtube, Twitch, 네이버 라이브쇼핑입니다. 고객이 원하는 경우 다른 채널도 추가될 수 있습니다.
- 서비스에 이상이 생겼거나 부정적인 채팅의 개수가 급증하는 경우 Slack이나 Email로 알람을 보냅니다.
- 문의 사항이 있으면 우측 하단의 문의하기 버튼으로 메일을 보낼 수 있습니다.
진행방식
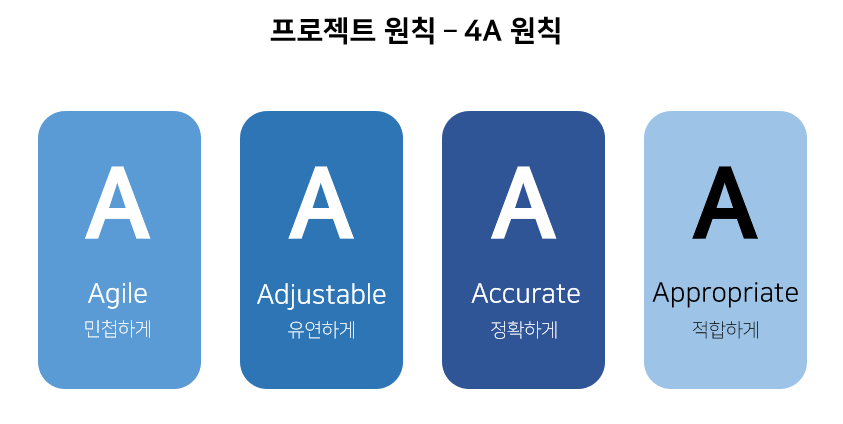
프로젝트를 진행할 때 4A 원칙을 준수했습니다.
- Agile : 프로젝트의 시간적 제약이라는 특성을 해소하고자 Agile 방법론을 도입했습니다.
- Adjustable : 유동적이라는 Agile 방법론의 특성에 맞춰 구성 변경 및 확장이 용이하고 플랫폼에 상관없이 사용이 가능한 Docker 환경을 선택했습니다.
- Accurate : 정확한 성능 지표 평가를 위해 프로젝트의 모든 요소를 시각화했습니다. Web의 경우 Logging 기능을 구현하여 웹에서 발생하는 모든 event를 log에 기록했습니다. 머신러닝의 경우 조건에 따른 결과를 한 눈에 파악하기 위해 성능평가 대시보드를 작성했습니다. 파이프라인의 경우 파이프라인 전체를 시각화하여 총 4개의 대시보드로 나타냈습니다.
- Appropriate : 서비스의 상용화가 목적이었기 때문에 합리적이고 적합한 방식으로 서비스를 개선하고자 했습니다. 이를 위해 Agile 방식을 사용하여 주기적으로 평가와 검토를 진행하였고, Accurate 원칙을 도입하여 머신러닝부터 파이프라인까지 모든 요소를 시각화 하고자 했습니다. 그 결과 머신러닝의 경우 Accuracy를 85.62%에서 88.76%로 증가시키고 Loss를 0.33에서 0.27로 약 20% 감소하는 성과를 거두었습니다. 웹과 파이프라인의 경우 웹 응답속도를 13초에서 5초로 8초 감소시켰습니다.
담당 역할
PM, Docker 환경으로 실시간 데이터 파이프라인 구축, 웹개발
역할1 Docker 환경으로 실시간 데이터 파이프라인 구축
21개 컨테이너 18개 서비스로 구성된 실시간 데이터 파이프라인을 Docker-compose 방식으로 구축했습니다.
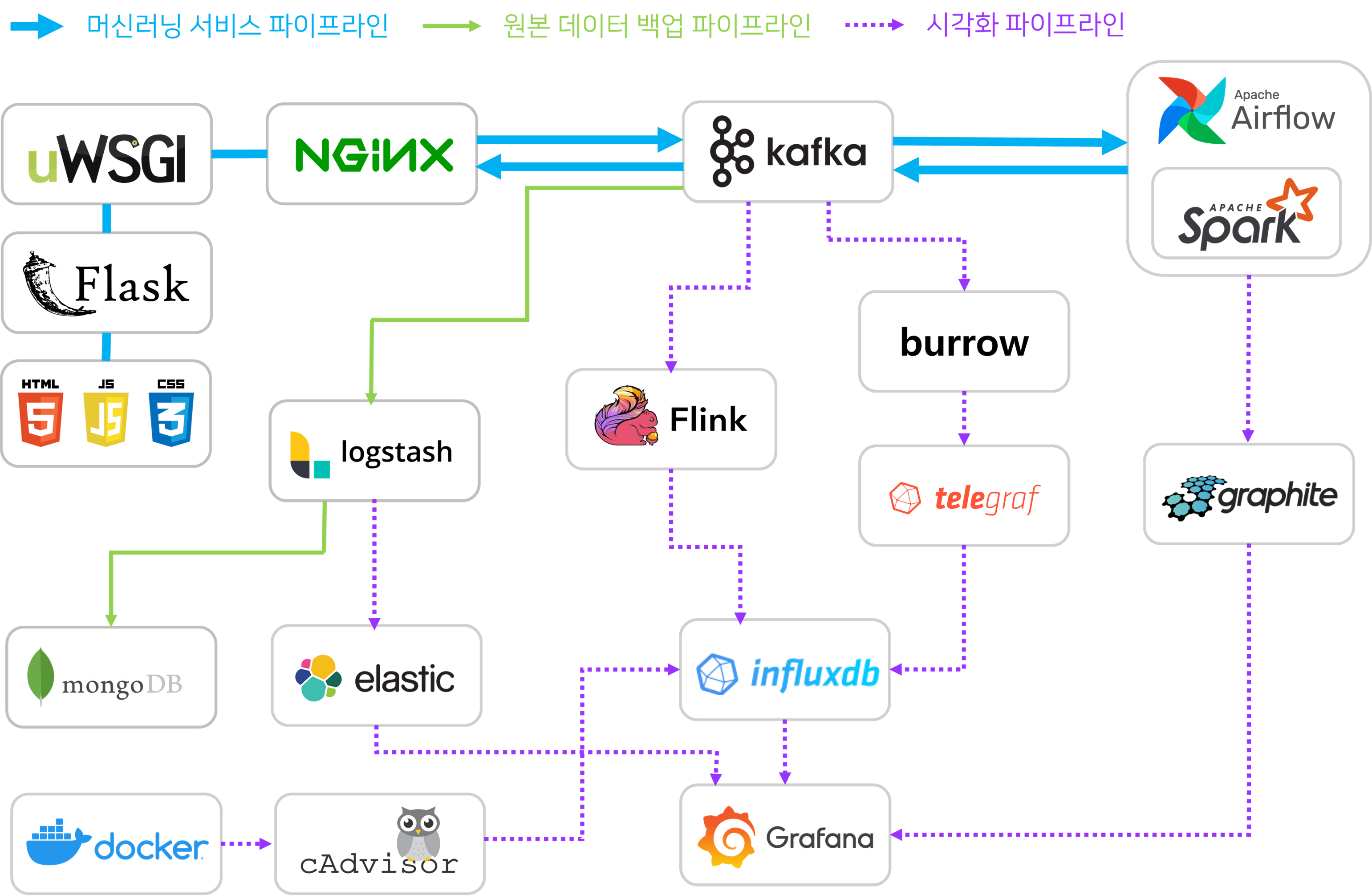
파란색 굵은 선으로 표시된 부분은 JAVAS의 핵심 파이프라인인 머신러닝 서비스 파이프라인입니다. 고객이 Flask 웹에서 방송 채널을 선택하고 URL을 입력하면 Flask 웹에서 해당 방송의 채팅을 스크레이핑합니다. 그 데이터를 메시징 시스템인 Kafka를 통해 Spark로 전송하면 실시간으로 머신러닝 분석하여 그 예측값을 다시 Kafka를 통해 웹으로 전송하는 구조입니다.
녹색 실선으로 표시된 부분은 원본 데이터가 저장되는 파이프라인입니다. Spark에서 예측값과 함께 채팅 원본 데이터를 Kafka로 전송하면 그 데이터를 logstash로 수집하여 MongoDB에 적재하는 파이프라인입니다.
보라색 점선으로 표시된 부분은 시각화 파이프라인입니다. 서비스의 핵심 파이프라인인 머신러닝 서비스 파이프라인의 각 요소를 시각화하고자 했습니다. 이를 위하여 시각화 대상을 Spark, Kafka, 웹서비스, 개발환경(Docker)으로 선정한 뒤 각각에 맞는 수집툴과 DB를 선택하여 아래와 같은 시각화 파이프라인을 구축했습니다.
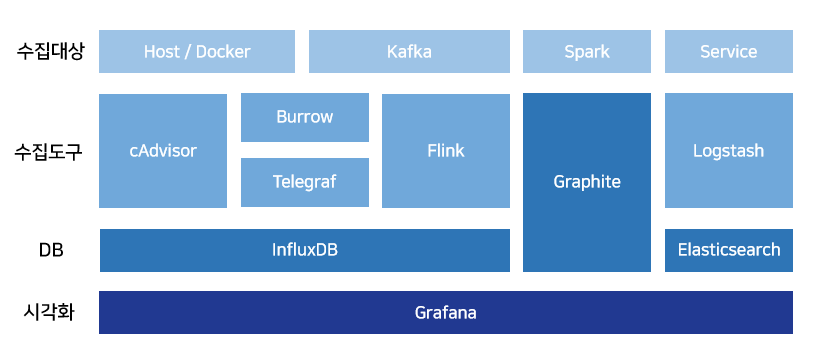
- Spark - Spark에서 자체적으로 제공하는 모니터링 데이터인 Spark matrics 데이터를 Graphite를 사용하여 수집, 적재했습니다.
- Kafka - Lag나 Offset과 같은 Kafka의 메타데이터를 LinkedIn에서 개발한 Burrow라는 툴을 사용하여 수집하여 Telegraf를 통해 InfluxDB에 적재했습니다. 또한, 각 토픽을 통해 전송되는 메시지의 개수나 데이터량은 Flink streaming을 사용하여 실시간으로 InfluxDB에 적재했습니다.
- 웹서비스 - 웹서비스에서 사용하는 예측값이나 채팅 메시지와 같은 데이터는 Logstash로 수집하여 Elasticsearch에 적재했습니다.
- 개발환경(Docker) - Telegraf와 cAdvisor를 사용해 데이터를 수집하여 InfluxDB에 적재했습니다.
- Graphite, InfluxDB, Elasticsearch에 각각 저장된 데이터는 Grafana를 사용해 시각화했습니다.
역할2 웹개발
Python Flask로 웹 서비스를 개발했습니다. 프론트엔드와 백엔드를 모두 담당했습니다.
- Python의 Multiprocessing으로 웹서비스를 담당하는 메인 프로세스와 채팅 메시지 스크레이핑 후 Kafka에 데이터를 전송하는 차일드 프로세스, Kafka에서 데이터를 수신받아 프론트엔드로 전송하는 차일드 프로세스 등 네가지 프로세스로 구성된 비동기 환경을 구성했습니다.
- Ajax로 실시간 채팅 뷰어와 실시간 워드 클라우드, 실시간 그래프를 개발했습니다. 그래프는 Highchart를 이용했습니다.
- iframe으로 Grafana 대시보드를 웹에 연결하였습니다.
- emailJS로 문의 메일을 보내는 기능을 개발했습니다.
저장소
https://github.com/younginshin115/21_hyu_javas
시연영상
문제 해결, 개선 사례
1. 머신러닝 서비스 파이프라인 반응 속도 개선
머신러닝 서비스 파이프라인 반응 속도를 개선하기 위해 두가지 방법을 사용했습니다. 첫번째로 GPU Docker 컨테이너를 사용하여 머신러닝 분석 시간을 0초 이하로 단축시켰습니다. 두번째로 Spark submit 방식을 사용하여 Spark streaming Batch 사이의 딜레이를 감소시켰습니다. 이 결과 반응속도를 13초에서 5초로 8초 감소시킬 수 있었습니다.
2. GIL 문제 해결
웹에서 스크레이핑이 진행되고 머신러닝도 진행될 가능성이 있어 스크레이핑과 머신러닝에 적합한 언어인 Python을 개발 언어로 선택했습니다. 또한, 웹서비스의 규모가 작기 때문에 상대적으로 가벼운 프레임워크인 Flask를 선택했습니다. 그런데 서버에서 페이지 전환과 동시에 스크레이핑 작업이 수행되면서 Python의 GIL(Global Interpreter Lock) 특성이 문제가 되었습니다. 스크레이핑 작업이 끝나길 기다리느라 다음 페이지가 로딩되지 않는 것입니다. 이 문제를 해결하기 위해 이전 Python 중급 강의에서 배운 Multiprocessing 모듈을 사용했습니다. 이론으로만 배웠던 Multiprocessing을 사용해 볼 수 있어서 좋았습니다.
3. 메모리 부족으로 웹이 종료되는 문제 해결
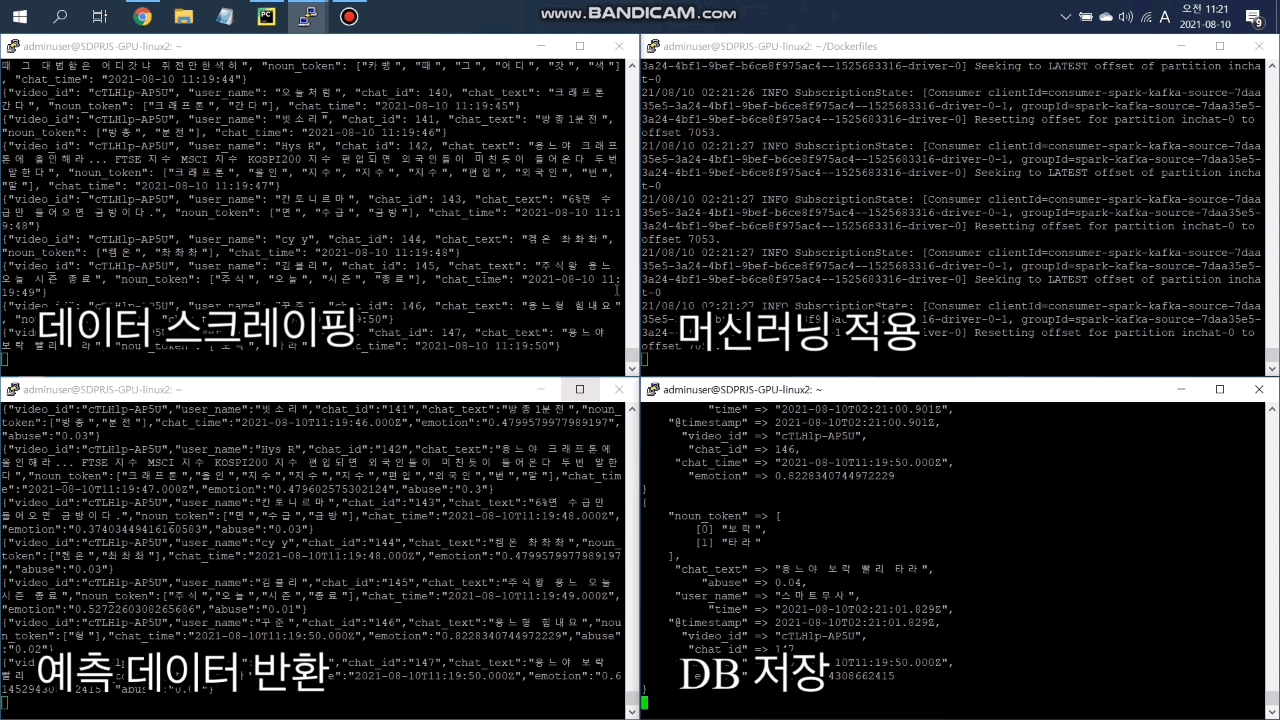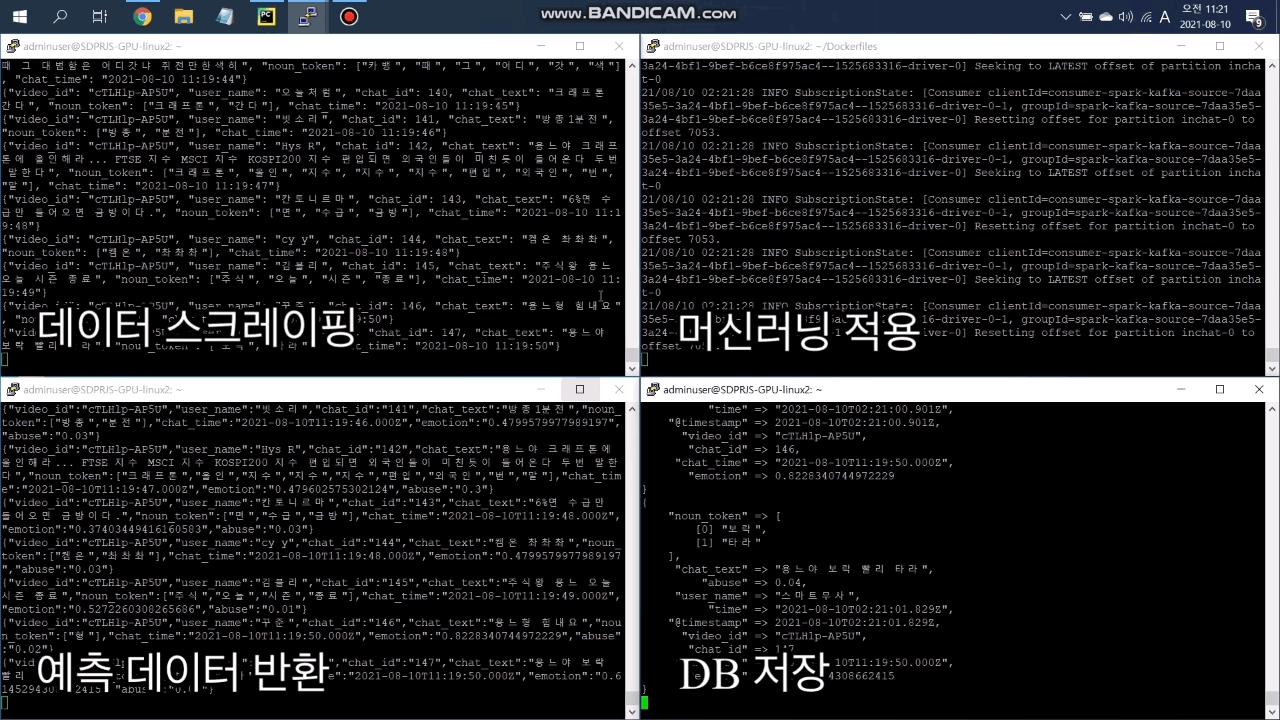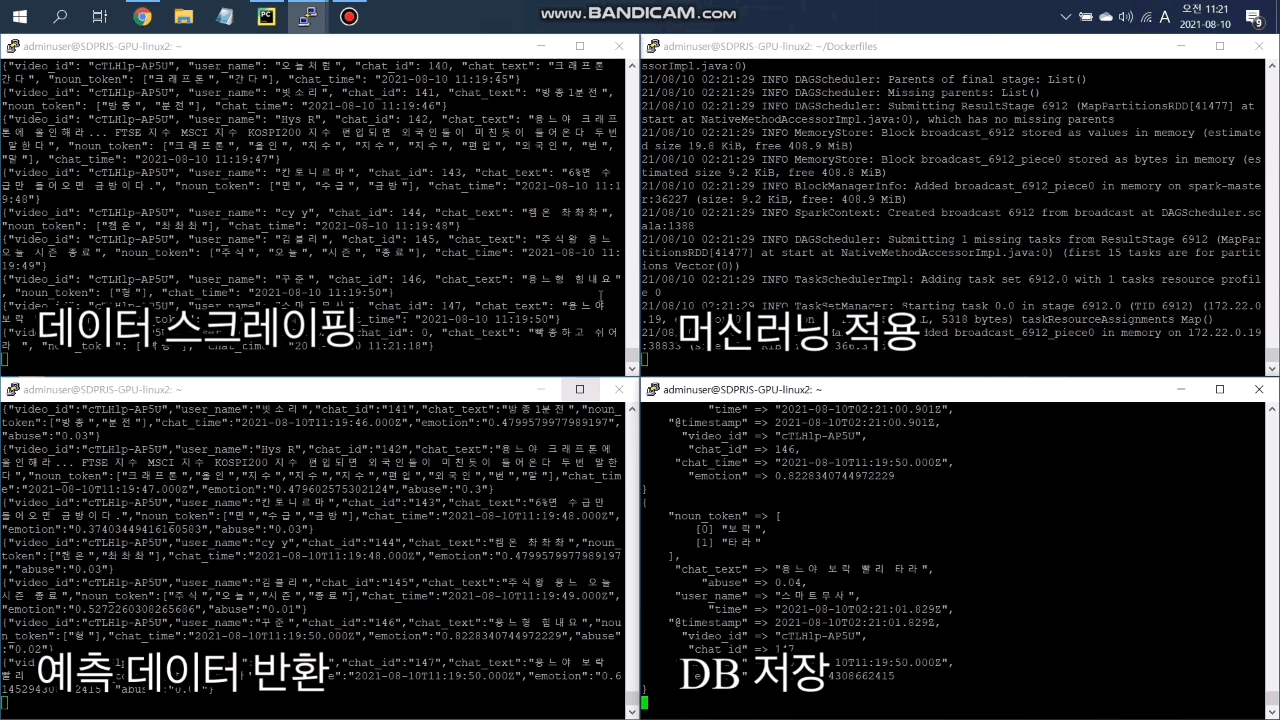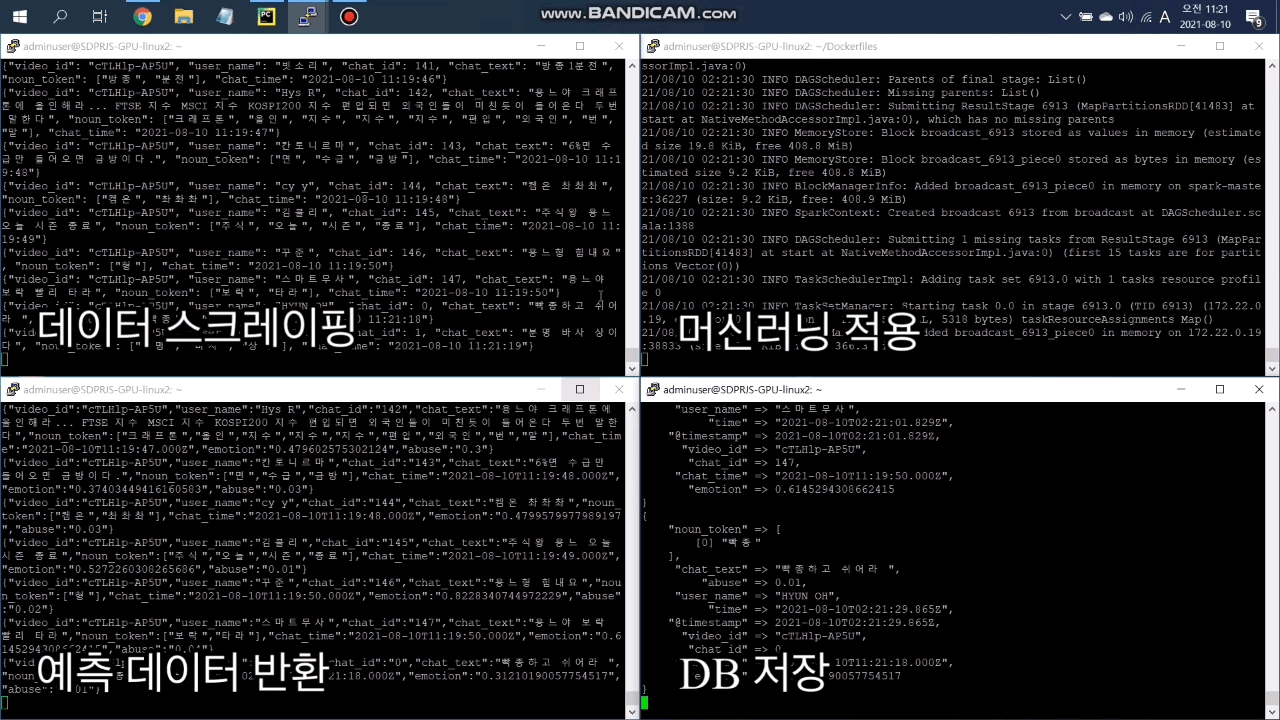
서비스를 시작하면 동시에 4개의 프로세스가 구동됩니다. 웹 서비스를 구동하는 메인 프로세스와 채팅을 스크레이핑하여 Kafka로 전송하는 첫번째 차일드 프로세스, Kafka에서 메시지를 수신받는 두번째 차일드 프로세스, 워드 클라우드를 생성하는 세번째 차일드 프로세스, 총 4개의 프로세스로 구성된 비동기 프로세스 환경입니다. 그런데 웹이 시작함과 동시에 아무런 오류 메시지 없이 종료되는 문제가 발생했습니다. 문제를 파악하기 위해 Logging 기능을 구현하여 메모리 부족이 문제라는 것을 확인했습니다. 각 모듈을 테스트하여 형태소 분석 모듈은 Konlpy가 메모리 부족의 원인이라는 것을 파악했습니다. 원래 메모리를 많이 사용하는 모듈인데 Kafka로 전송할 때도 머신러닝을 위하여 형태소 분석을 진행하고 워드클라우드를 생성할 때도 형태소 분석을 진행하여 한 번에 두곳에서 형태소 분석이 진행되며 메모리가 부족했던 것입니다. Kafka로 전송할 때 워드클라우드용 형태소 분석을 같이 시행하여 형태소 분석을 한 번만 진행되게 하는 것으로 문제를 해결했습니다.
4. 실시간 워드 클라우드 기능 개발
기업에서 실시간 워드 클라우드를 개발해달라고 요청했습니다. 고민 끝에 초단위로 워드 클라우드를 생성하여 ajax로 이미지를 교체하는 방식을 선택했습니다. 개발할 때 다음 사항을 고려했습니다.
- 캐시 문제를 해결하기 위해 이미지 생성할 때 마다 새로운 이미지 명을 생성한 후 클라이언트로 전송했습니다.
- 간혹 연결 문제로 이미지가 뜨지 않는 경우 로딩 이미지가 대신 뜨도록 설정했습니다.
- CORS 이슈가 발생하여 관련 옵션을 프론트엔드와 백엔드에 추가했습니다.
- 4시간씩 테스트하여 워드 클라우드용 단어 집합의 개수를 최적화했습니다.
5. Nginx Timeout 문제 해결
서버와 연결한 이후 서비스가 504 에러와 함께 멈추는 문제가 발생했습니다. Flask와 uWSGI의 로그를 확인한 결과 관련 오류 메시지는 보이지 않았고 Nignx 로그에서 upstream timed out 오류가 발생하는 것을 발견했습니다. 라이브 방송이 종료되면 계속 읽기와 연결을 시도하다가 해당 오류가 발생하는 것으로 추측되었습니다. Nignx의 응답시간을 5분으로 늘려준 뒤 ajax에 timeout 옵션을 설정하여 일정시간(5분 이상) 연결되지 않으면 에러메시지를 표시 후 home 화면으로 돌아가도록 설정하여 문제를 해결했습니다.
6. 기타 문제
- 시각화 파이프라인을 구축하는 동안 시각화 팀에서 미리 작업을 진행할 수 있도록 Python을 이용하여 임시 데이터를 생성하여 InfluxDB에 적재했습니다.